AI Can't Read an Investor Deck




AI failures modes when we pushed frontier models on real finance tasks
Last fall, the Wall Street Journal reported that 23% of job-seeking Harvard MBAs were still looking for work three months after graduation. Then, last month, Anthropic published research on labor market impacts of AI that placed financial analysts among the ten most exposed occupations to AI displacement.
The anxiety is understandable. But we think it's premature.
We've stress-tested frontier AI models on financial reasoning tasks that are representative of real work in earnings analysis, deal evaluation, and investor decks. What we found suggests a meaningful gap between how these models perform on standard benchmarks and how they perform when you hand them complex, multimodal inputs that real investors work with everyday.
When you give a model real-world finance inputs that combine charts, graphs, and images, instead of typed-out numbers, accuracy diminishes substantially. GPT-5.4, Gemini 3.1 Pro, and Claude Opus 4.6 consistently fail in two ways: misreading values from dense visual documents, and applying the wrong financial operation even when the inputs are correct.
The setup
We constructed 25 tasks based on real financial documents: earnings reports, investor presentations, roadmap slides, and regulatory fee schedules. Each task requires identifying specific numbers from a document and performing a financial calculation - a margin, a growth rate, a dilution percentage, a ratio. Each task has a single correct numerical answer so scoring is unambiguous: pass or fail.
We started with the original image of the document page (image-only) and then constructed a text-only version by writing out the information from the image in free text. This lets us separate two failure modes that standard benchmarks conflate: can the model do the math? versus can the model read the document?
We tested three frontier models: GPT-5.4, Gemini 3.1 Pro, and Claude Opus 4.6 across both variants, for 50 evaluations per model (25 tasks × 2 variants). Each model receives the same prompt with the same evidence. If the model’s final numerical answer falls within a defined tolerance of the ground truth, it passes.
What we found
Models need to read the document to reason correctly
Before running the full eval, we ran a sanity check: we gave each model only the question with no other sources, and asked it to answer from parametric knowledge alone.
The results are decisive. Across the 25 tasks, Claude Opus 4.6 answered 1/25 correctly (4%), GPT-5.4 answered 1/25 (4%), and Gemini 3.1 Pro answered 0/25 (0%). Claude Opus 4.6 and Gemini 3.1 Pro only passed one task, task_136 (shelter’s CPI contribution ratio = 3.0×), which is a small integer answer that two models guessed correctly by chance.
This demonstrates that the benchmark is genuinely testing document reasoning, not recall of memorized financial figures.
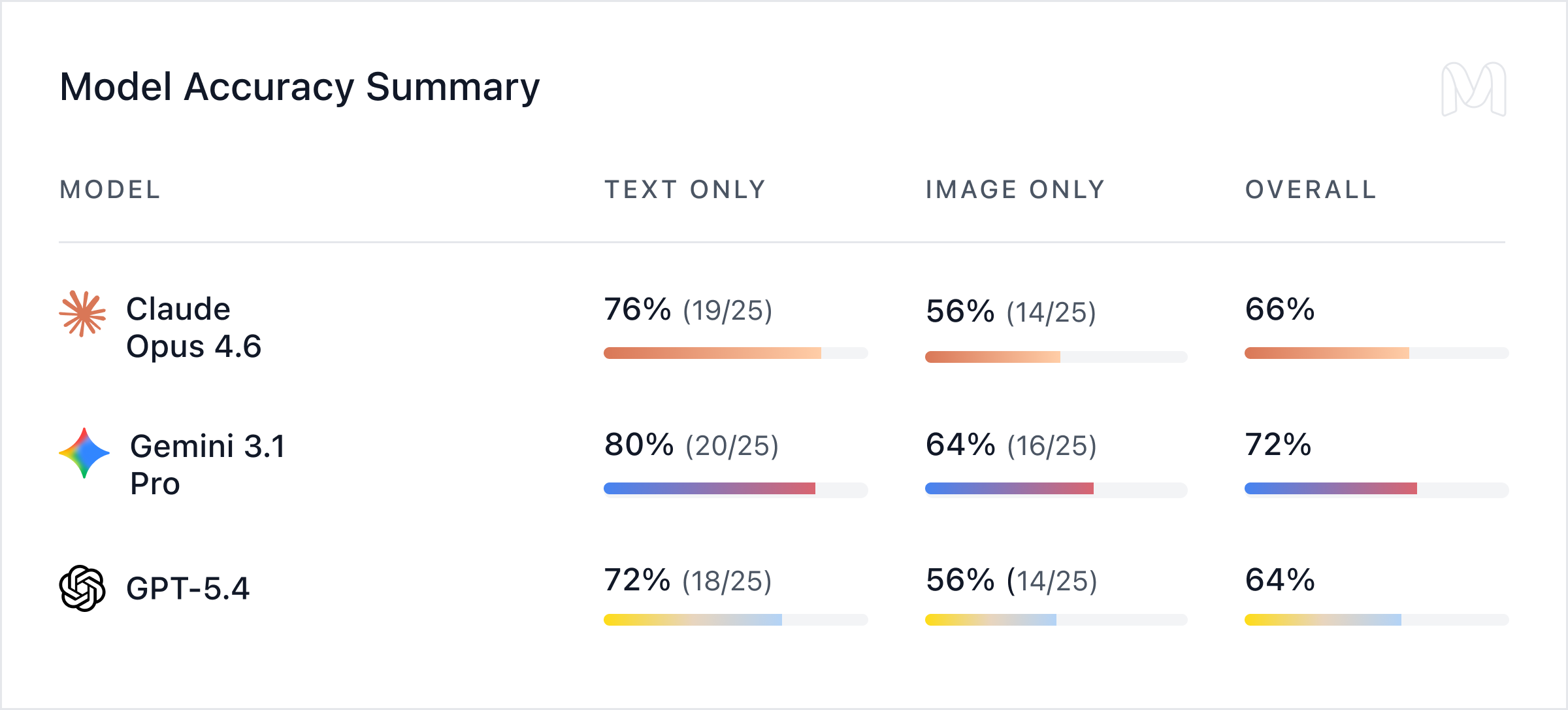
Models perform better on text than images
When provided with clean extracted text, model performance is credible: text-only accuracy ranged from 72% (GPT-5.4) to 80% (Gemini 3.1 Pro), with Claude Opus 4.6 at 76%. When provided with only the document image, accuracy dropped to between 56% and 64%, a decline of 16 percentage points for Gemini 3.1 Pro and GPT-5.4, and 20 percentage points for Claude Opus 4.6.
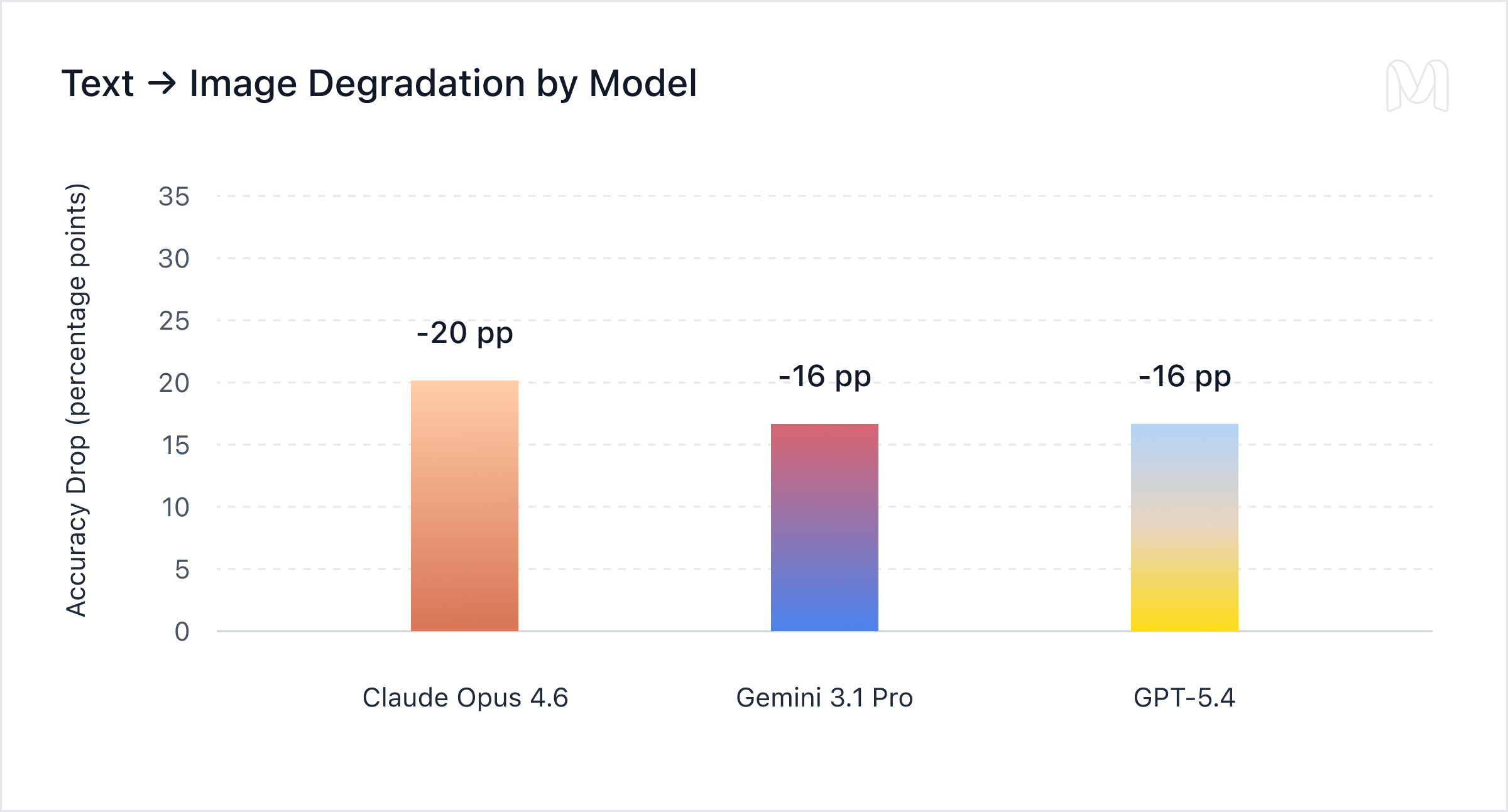
The text-to-image degradation is strikingly consistent: -20pp for Claude Opus 4.6, -16pp for Gemini 3.1 Pro, and -16pp for GPT-5.4. They point to a general weakness in even frontier models. Visual extraction from real financial documents is a bottleneck for every frontier model, not a quirk of any single one.
The same task, different results
The clearest illustration of the text-vs-image gap comes from task_138, a Fidelity Rising Wedge pattern task. The question asks for the dollar difference between the upper and lower trend lines at the entry point.
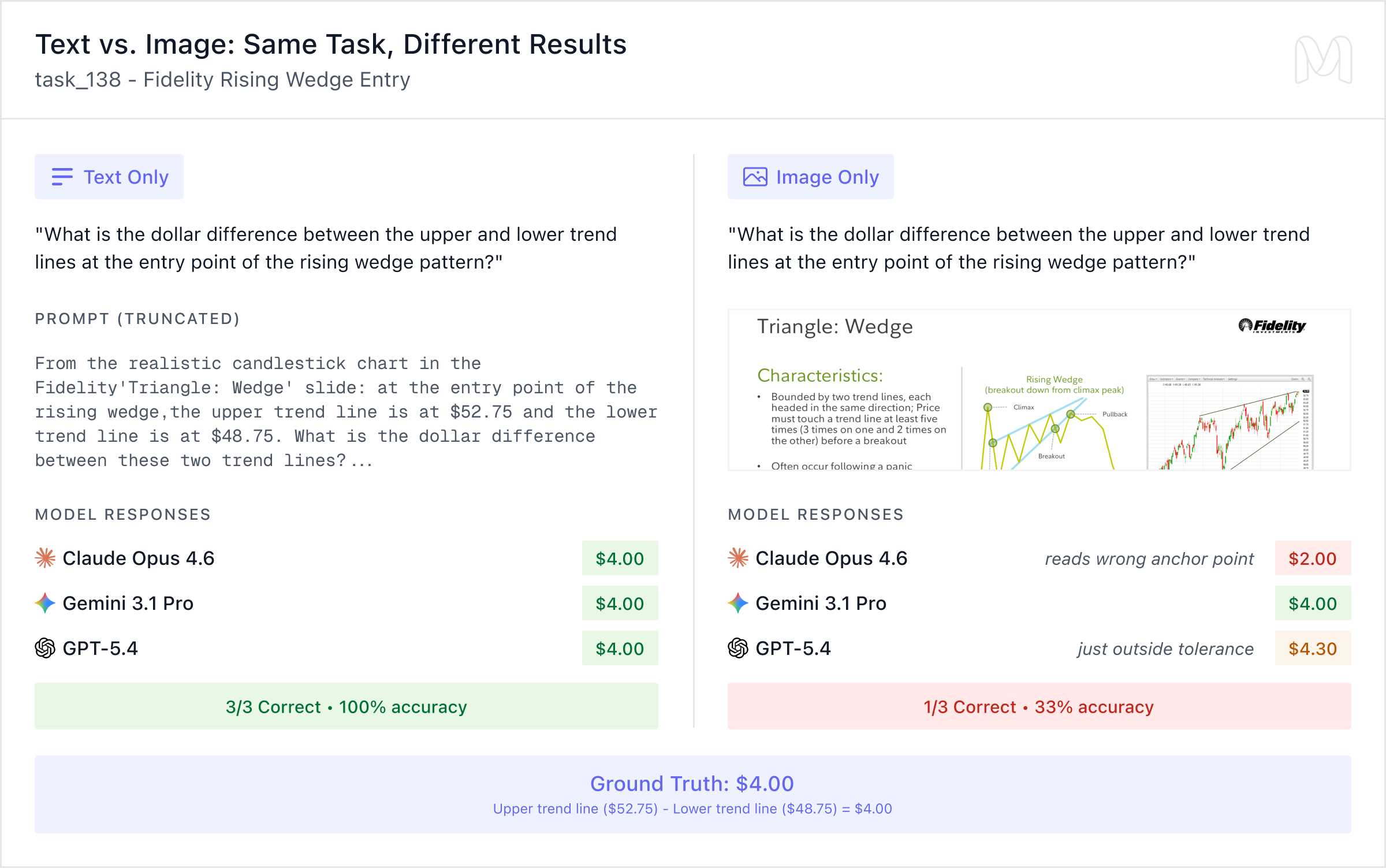
In the text-only condition, all three models answer correctly ($4.00). In the image-only condition, only Gemini 3.1 Pro gets it right. Claude Opus 4.6 reads the wrong anchor point and returns $2.00. GPT-5.4 lands just outside tolerance at $4.30. The model knew exactly how to compute the final value but it couldn’t reliably read the value off the chart.
Two failure modes drive the collapse
When we dug into why image-only accuracy drops so consistently, two patterns emerged:
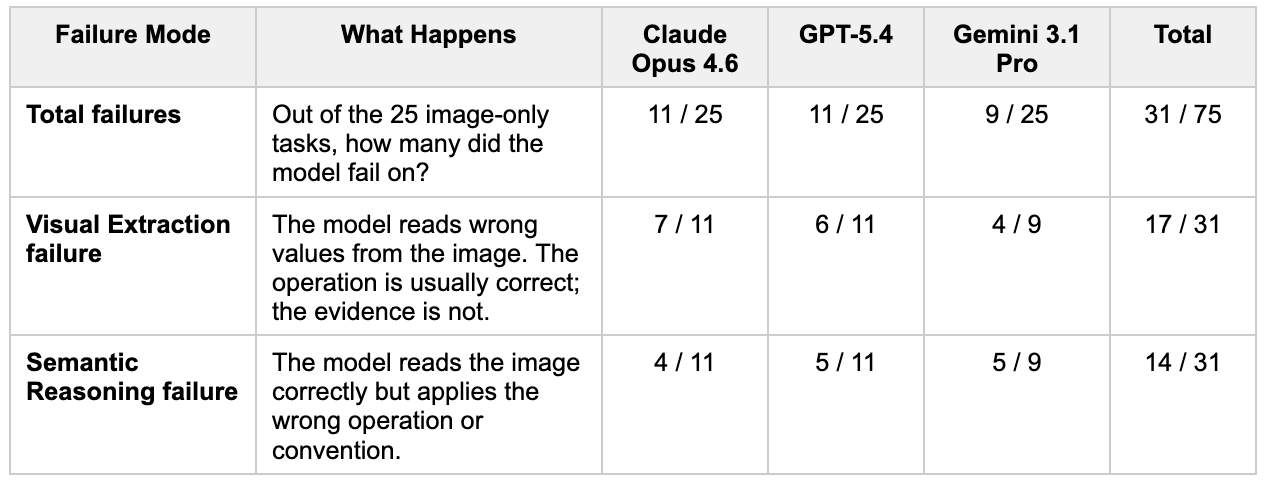
Visual extraction is the main cause of why models fail on the image-only tasks. They often anchor to the wrong element in dense charts, especially in documents with multiple graph types on a single page, and pull a plausible but incorrect value when the question does not explicitly specify where to look. This is a real-world problem – usually, models have to identify the relevant region from an image rather than being guided to a specific value.
The reasoning failure is less visible but more informative. Even when models have the correct values in front of them (in the text-only condition, where extraction is not a factor), they sometimes apply the wrong financial operation. For example, returning an absolute difference instead of a percentage change, or inverting a ratio. These are standard calculations, suggesting that the issue is not complexity but how models execute multi-step financial reasoning.
Sometimes, both failure modes appear together. In these dual-failure cases, models first extract the wrong values from the image, and then compound the error by reasoning about those values incorrectly.
Why this matters
Standard AI benchmarks don’t represent real financial work. In contrast to existing chart and document benchmarks like ChartQA and DocVQA, which often use cleaner layouts or isolate a single visual element, our tasks are drawn from dense, real financial documents and require identifying the correct values before reasoning over them. Yet in practice, investors have to review messy data, like 40-page PDFs with nested tables, multi-panel charts, margin bridges, and footnotes.
Our results suggest that frontier models currently handle the visual extraction step far less reliably than the topline benchmark scores suggest. The industry’s trajectory toward improved visual reasoning is clear. But before the conversation about AI displacing financial analysts goes further, it’s worth asking: what exactly are models impressive at, and under what conditions?
If you’d like to see our full methodology, task specifications, samples, and per-task failure mode analysis, please reach out here.