Expert data drives model performance



How Mercor’s data and Applied Compute’s long-horizon RL unlock real capability gains for AI models
Mercor partnered with Applied Compute to post-train an open-source model using one of our expert-labeled dev sets, resulting in substantial performance gains on the APEX-Agents benchmark.
With fewer than 1,000 high-quality data points from Mercor, the post-trained model's Pass@1 and mean score nearly doubled. On the corporate law evals, the Pass@1 score tripled. The training trendline is near-linear, indicating that additional data would likely keep yielding performance gains.
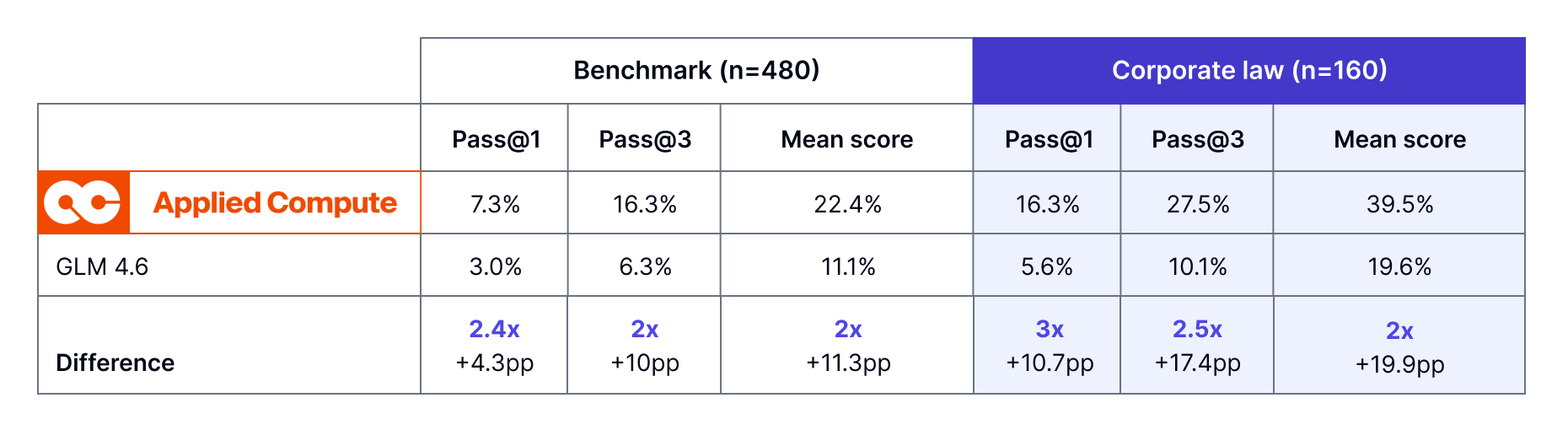
APEX-Agents assesses whether agents can execute the real day-to-day work of investment banking analysts, management consultants, and corporate lawyers. There are 480 tasks, created by a team of Mercor experts: Vice Presidents, Managing Directors, and Managers with 10+ years of experience at top-tier firms. They simulated the demands of the profession to challenge agents to navigate instructions, use a range of applications, manage complicated file systems, and plan over long horizons. See the technical report for more details. You can also download the dataset and all of the files from Mercor’s Hugging Face and our infra service, Archipelago, from our GitHub. For this experiment we used the full benchmark (n=480), measuring Pass@1, Pass@3, and mean criteria passed.
Training set up
Mercor provided a dev set of 874 tasks for post-training, split across 50 unique “worlds” of data that represent a scenario. Each world has data and applications that can be found in a real enterprise environment, such as Google Sheets, Docs, and Code Execution. None of the tasks or worlds appear in the APEX-Agents benchmark.
Applied Compute deployed its proprietary long-horizon RL stack to stress-test data quality under realistic training dynamics and measure whether gains transferred to the hardest APEX-Agents tasks. Training was performed single-epoch with no SFT warmup, no filtering, and no task or rubric modifications. Two held-out worlds per domain were reserved for validation to detect overfitting.
Applied Compute evaluated frontier and open-weight models on APEX-Agents to establish baseline capability and identify where learning was possible. GLM 4.6, a mid-scale 355b parameter MoE model with 32b active parameters, emerged as an appropriate model to start from, offering the right tradeoff between iteration speed and baseline competence. It scores 3.8% with Pass@1 and 12.1% based on mean score, which is typical for an open-source model on APEX-Agents.
Results and continued training gains
The post-trained model outperforms the baseline across all metrics, with the largest gains in corporate law (Table 1).These improvements come from just 874 expert-labeled tasks. In a low-data regime, the dominant risk is not under-training the model, but misallocating scarce expert effort.
RL training and evaluation reduced this risk by turning each run into a high-signal measurement. By running end-to-end RL with detailed behavioral observability, Applied Compute enabled Mercor to see how much benefit was being delivered by the data, demonstrating that hundreds, not tens of thousands, of examples are sufficient to drive real gains.
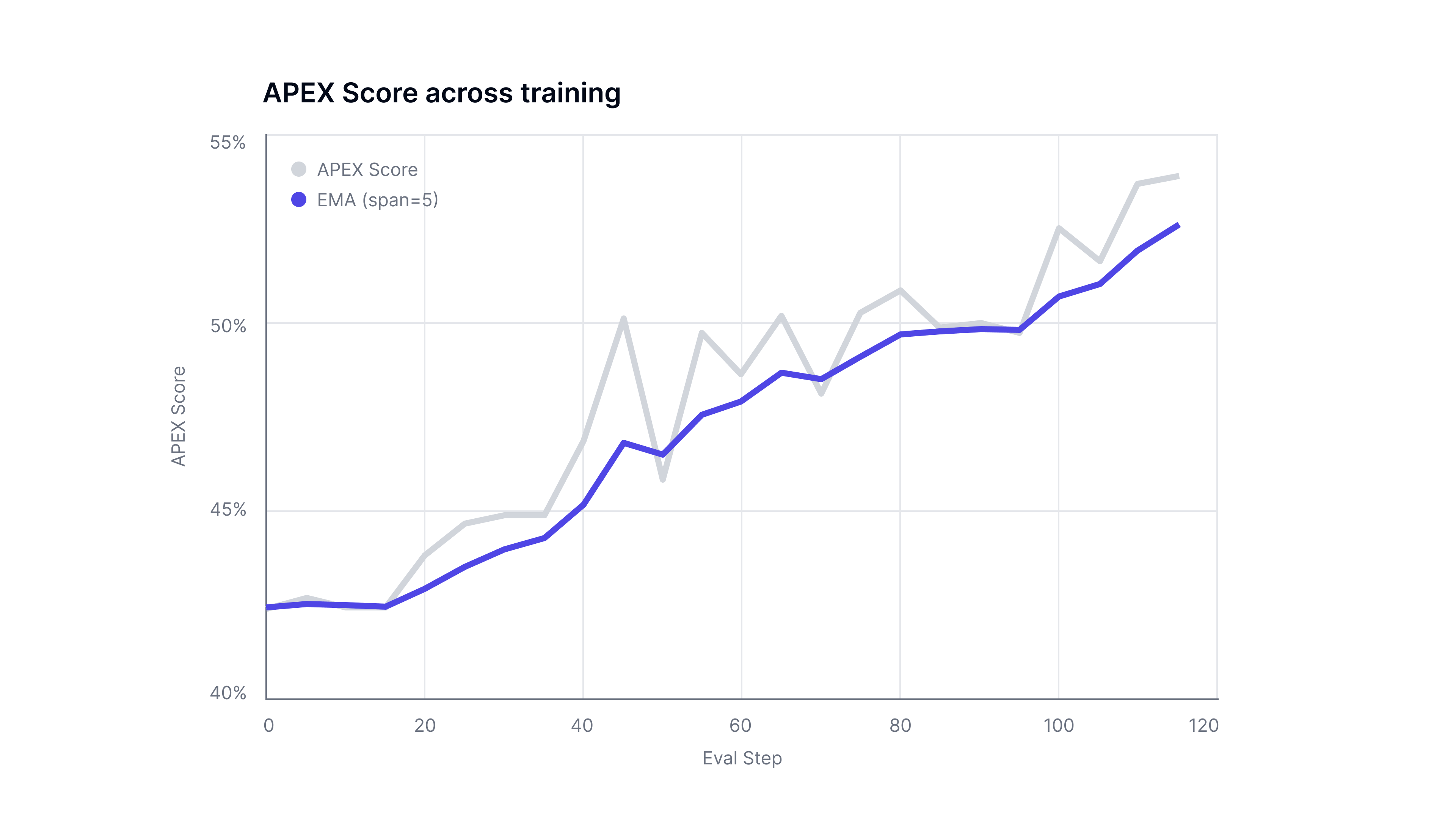
Full trajectory-level observability showed how models attempted tasks, allowing Applied Compute to distinguish learning from undesirable behaviors like refusal or premature termination that can be masked in aggregate metrics. Targeted ablations over reasoning budget, tool access, and training configuration were evaluated against optimized prompt baselines to isolate training gains. When issues were identified, fixes were validated through retraining without adding new data. Training eval trendlines showed consistent improvement. Gains across law, banking, and consulting were close to linear, which is atypical in data-limited settings and signals strong alignment between the data and target capabilities. Rapid feedback from training runs allowed expert effort to be redirected toward concrete gaps instead of expanded uniformly. We anticipate that similar amounts of high-quality data will continue to deliver benefits.
Example trajectory
One of our worlds (see below) shows a corporate lawyer on a due diligence project, tasked with analyzing whether the company’s shareholder payouts comply with US tax law. The world contains a full suite of corporate records: shareholder agreements, the distribution schedule, the original S-Corp election filing form, and a reference copy of the tax code that governs S-Corporations.
The baseline model produces a professional looking but factually flawed memo that incorrectly states that the corporation is in substantial compliance with US tax code. It used 18 tool calls and worked linearly. It listed files, read the distribution schedule and tax returns before submitting its final answer. The baseline model took the documents at face value and justified compliance despite evidence that proved otherwise. It correctly found the shareholder and payment records, but assumed the distribution matches the ownership stakes rather than checking.
In contrast, the post-trained model correctly states that the company is non-compliant. It also finds out that one shareholder was overpaid in 2022 and 2024 by correctly citing 26 USC §1366(a)(1) regarding the failure of pro-rata allocations and stating that the transfer to one individual violates §1361(b)(1)(C). The post-trained model improved in its reasoning and planning. It spent 9 steps just on reading specific US tax code sections, then executed several Python scripts to check the math on the distributions. It even performed a self-correction when it realized it hadn't completed its checklist.
Conclusion
This experiment demonstrates that quality datasets can push open-source models to unlock new capabilities, adopting the rigorous approach required for high-stakes professional work. With under 1,000 tasks and one epoch of training, we saw dramatic improvements and have high confidence in further gains from adding more data. The benefits of expert-created specialized data will only increase as training stacks adapt and models become more capable. Run evals yourself on APEX-Agents now.