Generalization Results from Training on the APEX-Agents Dev Set

In a previous post we post-trained GLM-4.7 on an agentic dev set to create AC-Small, a model that rose from 17th to 4th on the APEX-Agents leaderboard. The obvious remaining question: did the model just learn to improve on the held-out benchmark or did its capabilities actually improve?
To find out, we tested AC-Small on three held-out industry benchmarks: Toolathalon, which evaluates agents on multi-step workflows spanning more than 600 tools; APEX, which evaluates non-agentic professional reasoning across four domains; and GDPval, the closest end-to-end analog to APEX-Agents.
Performance improved substantially across the board: +5.7 points on APEX, +8.0 points on Toolathalon, and +7.7 percentage points on GDPval.
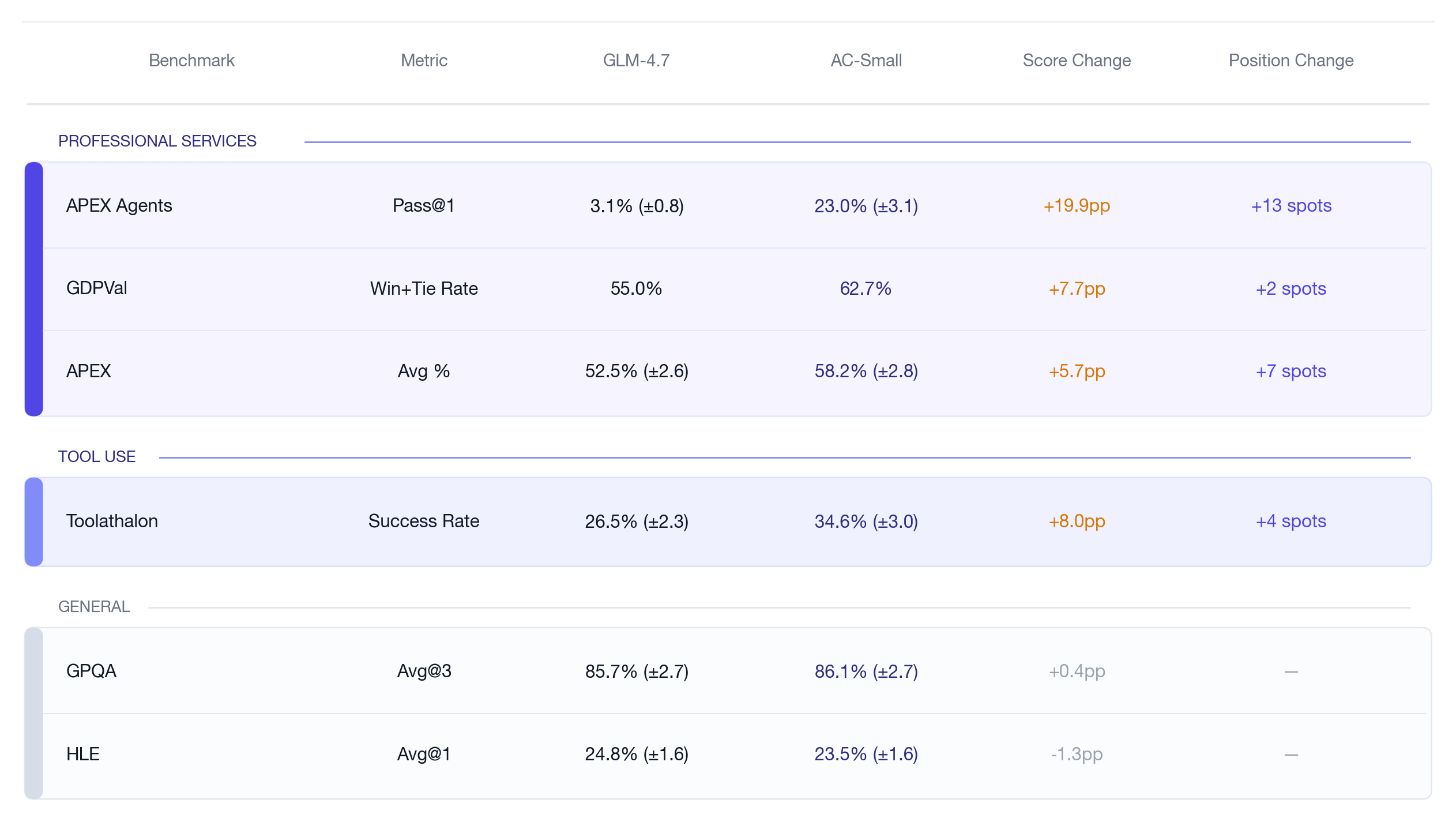
Table 1: General benchmarks stay flat, while held-out tool-use and professional benchmarks improve. HLE and GPQA are reported as Avg@1 and Avg@3 respectively. APEX intervals are derived from 8 runs per task. GDPVal is based on a single run and placement is based on the official leaderboard; Toolathalon result is based on 3 runs.
Results
GDPVal: Improved Performance on Economically Valuable Work
GDPVal measures professional work across 44 occupations and 9 sectors, judged by subject-matter experts. It is the closest held-out analog to APEX-Agents: an end-to-end test of whether the gains from training on APEX-Agents data generalized to out-of-distribution agentic tasks.
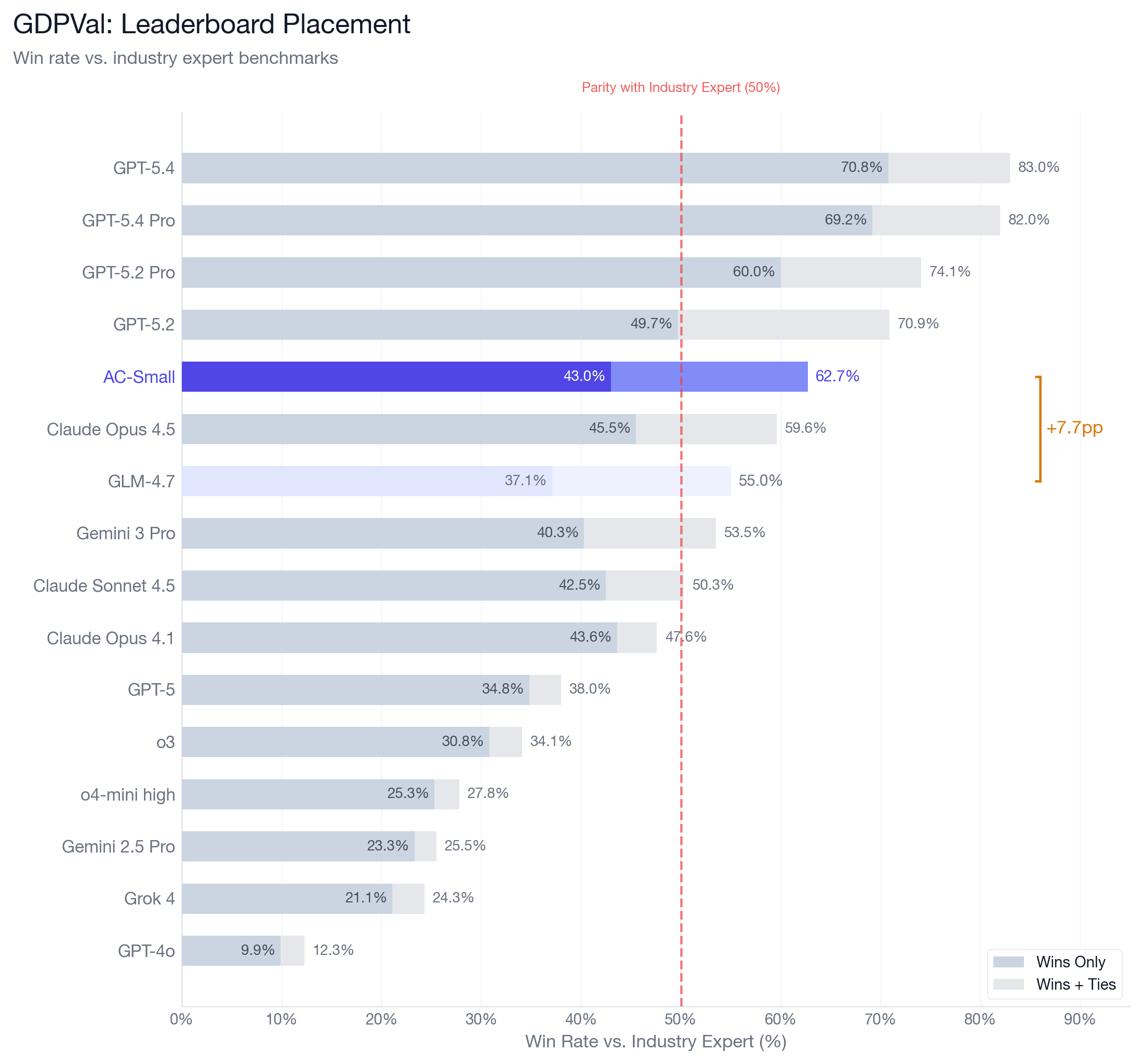
Figure 1: On GDPVal, AC-Small rises from 7th to 5th, surpassing Opus 4.5
We saw AC-Small’s win+tie rate rise from 55.0% to 62.7% (+7.7pp). If placed on OpenAI’s official GDPVal leaderboard alongside frontier models, AC-Small would rank 5th, behind GPT-5.4 (83.0%), GPT-5.4 Pro (82.0%), GPT-5.2 Pro (74.1%), and GPT-5.2 (70.9%), and ahead of Claude Opus 4.5 (59.6%).
Where the GDPVal Gain Comes From
Better Tool Use Across the Board
Toolathalon evaluates language agents on multi-step workflows across 32 software applications and 604 tools, requiring coordination across platforms over an average of 20 tool-calling turns. As an ablation it isolates tool-use fluency as a capability. AC-Small scores 34.6% versus GLM-4.7’s 26.5% (+8.0pp), lifting the model four spots on the leaderboard and past Claude-4-Sonnet, Kimi-K2.5, and Grok-4.
Better Professional Reasoning, Even Without Tools
APEX tests whether models can complete economically valuable work in management consulting, investment banking, law, and primary healthcare when they are given the exact files they need and no tool interaction is required. On this benchmark, AC-Small rises from 52.5% to 58.2% (+5.7pp), moving from 24th to 17th on the leaderboard.
The strongest single-domain effect is Medicine. AC-Small places 4th with a score of 64.8%, behind only Opus 4.6 Max (70.4%), Opus 4.6 High (70.0%), and Sonnet 4.6 (66.7%). That is notable because the training set solely covered tasks in law, consulting, and corporate finance.
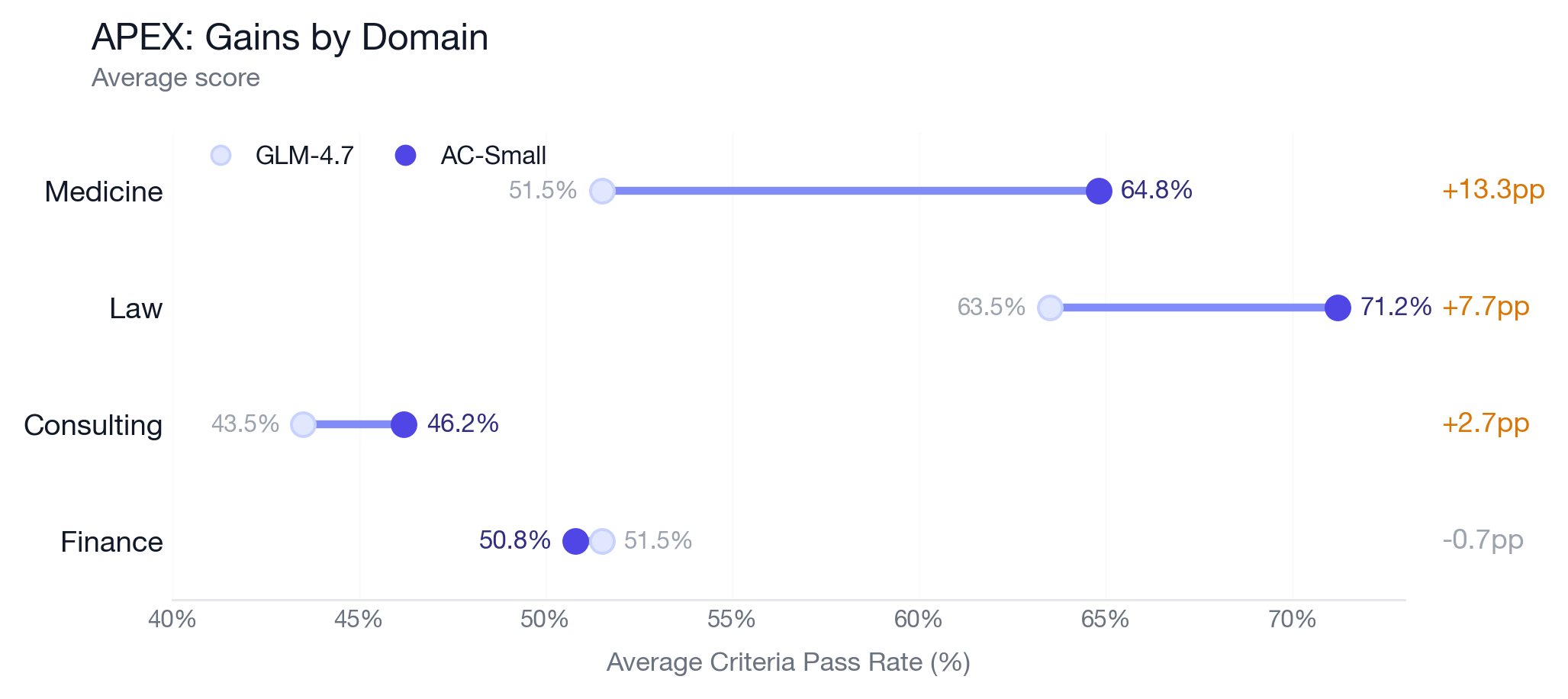
Figure 2: APEX gains concentrate in medicine and law, with smaller movement in consulting and a slight regression in finance that falls within the original confidence interval.
We dug deeper into how training on law, consulting, and banking could improve performance on medical tasks and found that the gains came from improved processes. For example, for one task in the medical eval set which asked for a diagnostic writeup, both models identified the right categories of tests, but GLM-4.7 dropped clinically significant details in its final answer. 4.7 omitted some veins that should be scanned, recommended colonoscopy without specifying biopsies, and listed only one source of false-negative troponin results. AC-Small preserved those sub-details, finishing the task with a perfect score.

Figure 3: An example task from APEX where AC-Small outscored GLM 4.7
What the Transfer Pattern Suggests
Taken together, these results suggest AC-Small gained capabilities that generalize beyond the dev set it was trained on. Toolathalon shows improved tool use. APEX shows better professional reasoning even without tools. GDPVal shows those gains translate to higher-quality end-to-end work as judged by a human-preference benchmark.
Beyond specific benchmark gains, AC-Small seemed to pick up some of the habits that lead to quality work output: preserving details, sanity checking intermediate outputs, and revising when those checks fail. These learnings allowed AC-Small to substantially improve on APEX medicine, a non-agentic domain that wasn't in the dev set it was post-trained on. This suggests that as expert data scales across the economy, models will become more useful not just because they know more, but because they work more like professionals.