Introducing the AI Consumer Index



Today, we're releasing our first version of the AI Consumer Index (ACE).
ACE tests what people actually want AI to do—from finding a gift for a friend to getting a custom recipe recommendation or fixing a hole in their drywall.
ACE contains realistic and challenging evals, split across shopping, food, gaming and DIY, created by experts from the Mercor platform. We are excited to share our new leaderboard, technical report, open source dataset, and eval harness.
Results
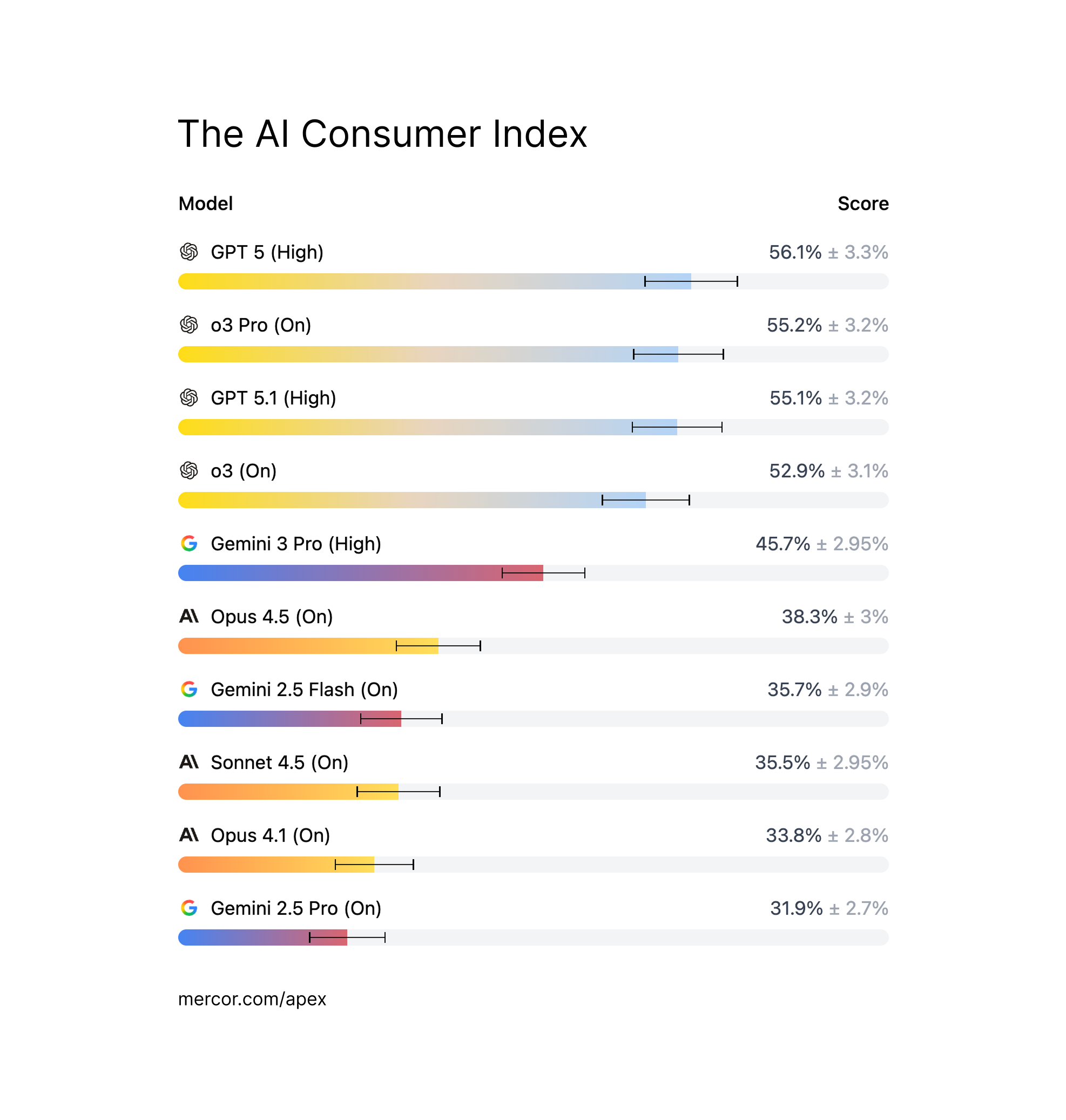
We show that models routinely fail on consumer tasks—GPT 5.1 (Thinking = High) is the top model but scores only 56.1%. The next best models are GPT 5 (Thinking = High) and o3 Pro (Thinking = On). The best performing model from Google is Gemini 3 Pro (Thinking = High) and from Anthropic is Opus 4.5 (Thinking = On), showing how the latest model releases are steadily improving at consumer tasks.
We see substantial differences in model performance across the four domains. No models score over 50% on Shopping tasks, an opportunity worth $5+ trillion globally – but models perform much better in Food. GPT 5 (Thinking = High) hits an impressive 70%, beating out the next best model by 10 percentage points. In DIY and Gaming we see the biggest range, with model scores ranging from 28% to 61%. Beyond these high-level stats we see a lot of tasks where models fail, often scoring under 25%.
Grading approach
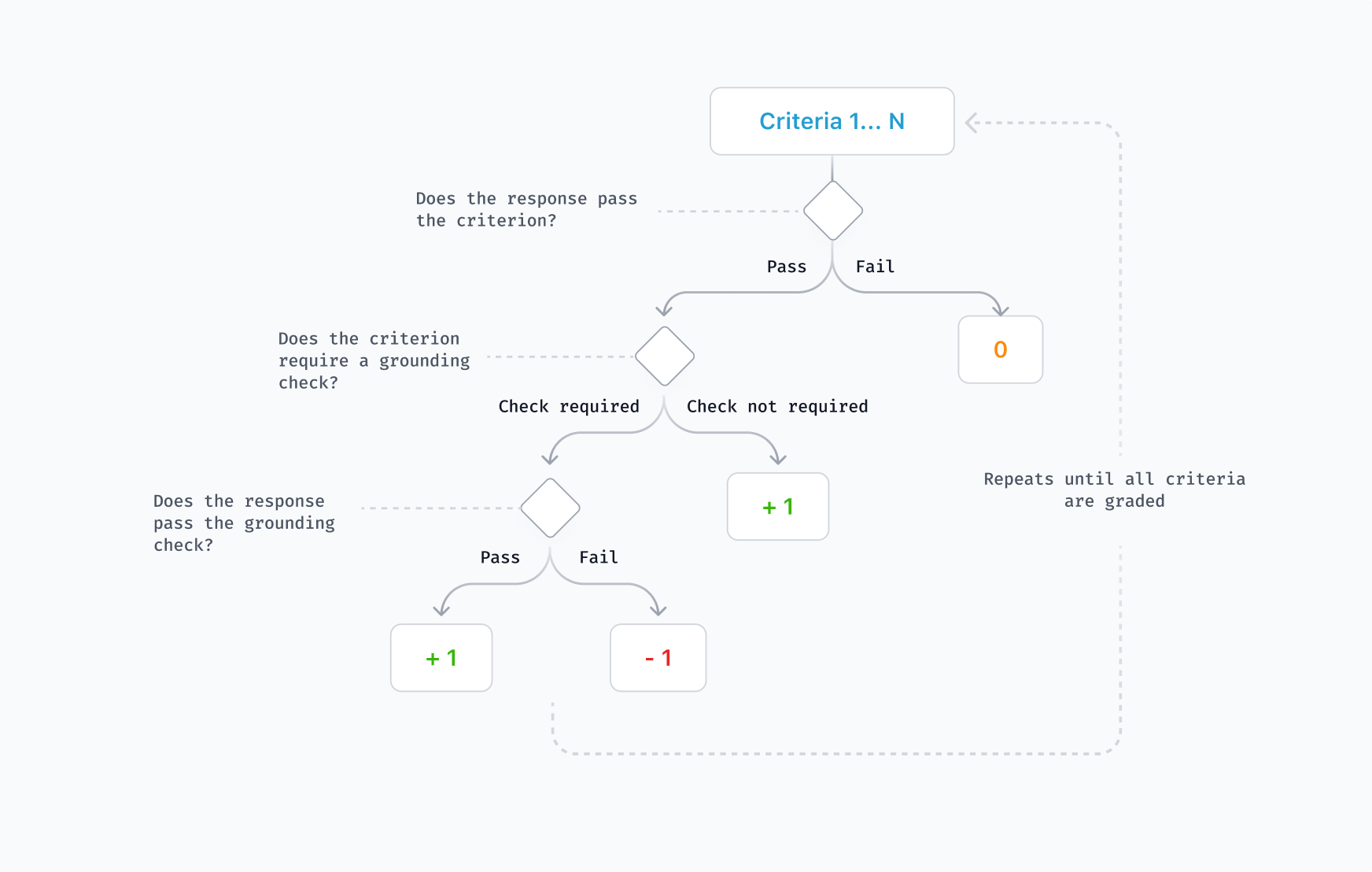
We introduce a novel rubric-based evaluation methodology with ACE.
Each task has a rubric of prompt-specific criteria to scalably grade model responses. Every rubric contains at least one hurdle criterion that must be passed before further rewards can be unlocked. The hurdles require the model to meet the user’s core objective -- such as, in Shopping, returning the requested type of product or, in DIY, providing a solution to the user's problem. The hurdles are important for minimizing the risk of reward hacking. We do not want to reward responses that are mostly irrelevant but still meet a specific requirement (e.g., the response returns any item under $50).
We also add grounding criteria that penalize models for making claims that are not supported by the retrieved web sources (i.e., hallucinating) or providing non-working links. These account for 42% of Gaming criteria and 74% of Shopping criteria, and do not appear in DIY or Food tasks. GPT 5.1 (Thinking = High) is the most grounded model, failing just 29% of the grounding criteria, whereas Gemini 3 Pro (Thinking = High) is the least grounded, failing on 62%.
Loss analysis
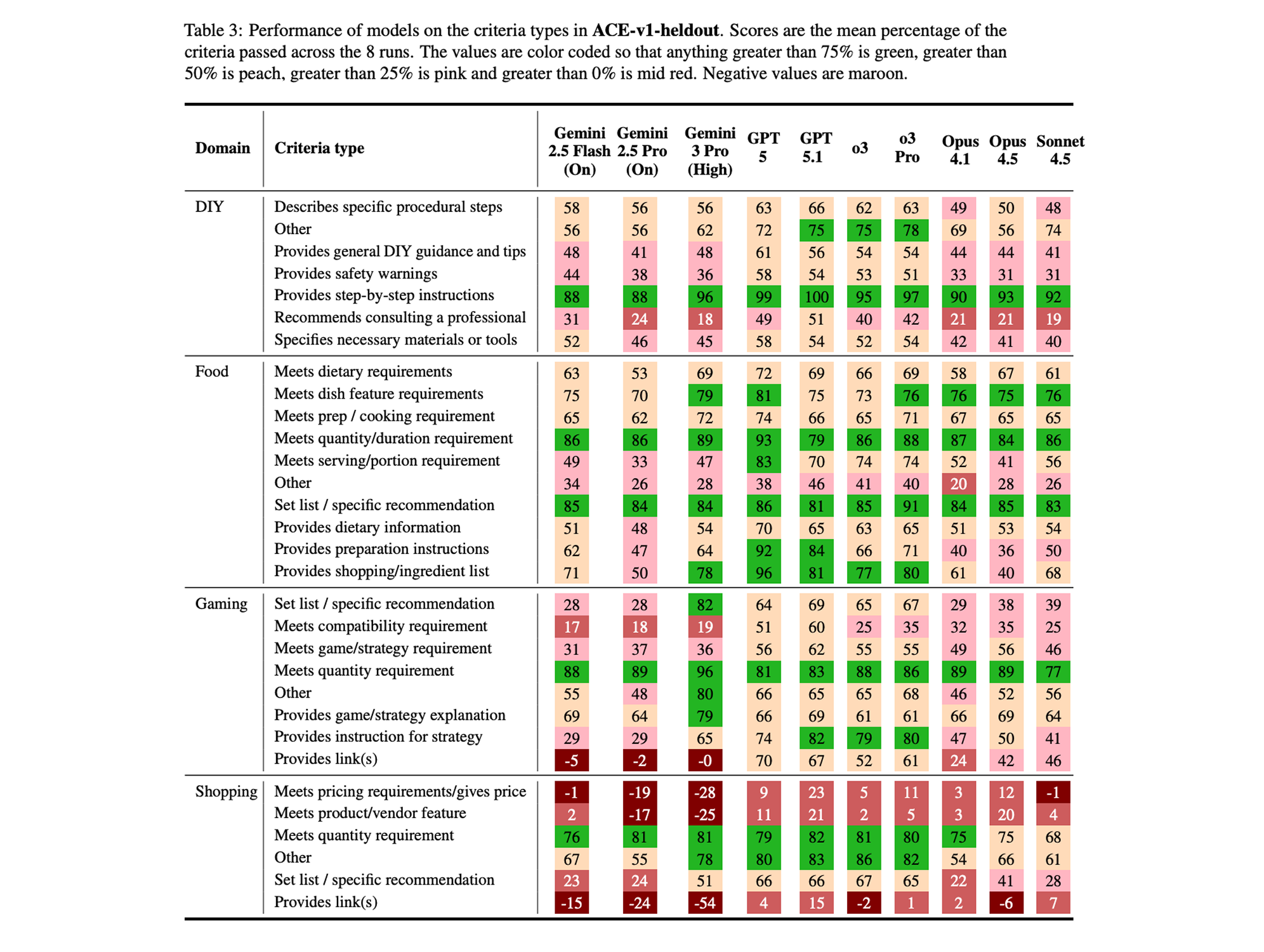
We built ACE to provide fine-grained insight into the performance of models – and every item in the rubrics are tagged with the criteria type, which can be used for loss analysis of model performance.
For instance, ACE shows that models perform well at meeting quantity requirements (nearly all models score 80% on this criteria type in Food) but they are much worse at meeting nuanced requests, like compatibility requirements in Gaming (most models score under 40%) or providing suitable safety warnings in DIY (most models score under 50%). For some criteria types, models find them so difficult that their mean score is actually negative – like providing working links or giving the price.
Open sourcing
We are open sourcing 20 cases in each of the four domains (n = 80 total) on Hugging Face. The data has a similar composition and is similarly difficult to the hidden heldout set. You can also use our evaluation harness (now on Github) to reproduce our grading approach. If you build with ACE, please let us know. To submit your model for testing, email [email protected]
ACE is only possible because of the incredible work of our experts. Thank you to everyone who took part in the project!