Scaling Data leads to SOTA Legal Performance on APEX-Agents




Applied Compute's model, trained on Mercor’s agentic data, is now top of the APEX-Agents leaderboard in corporate law
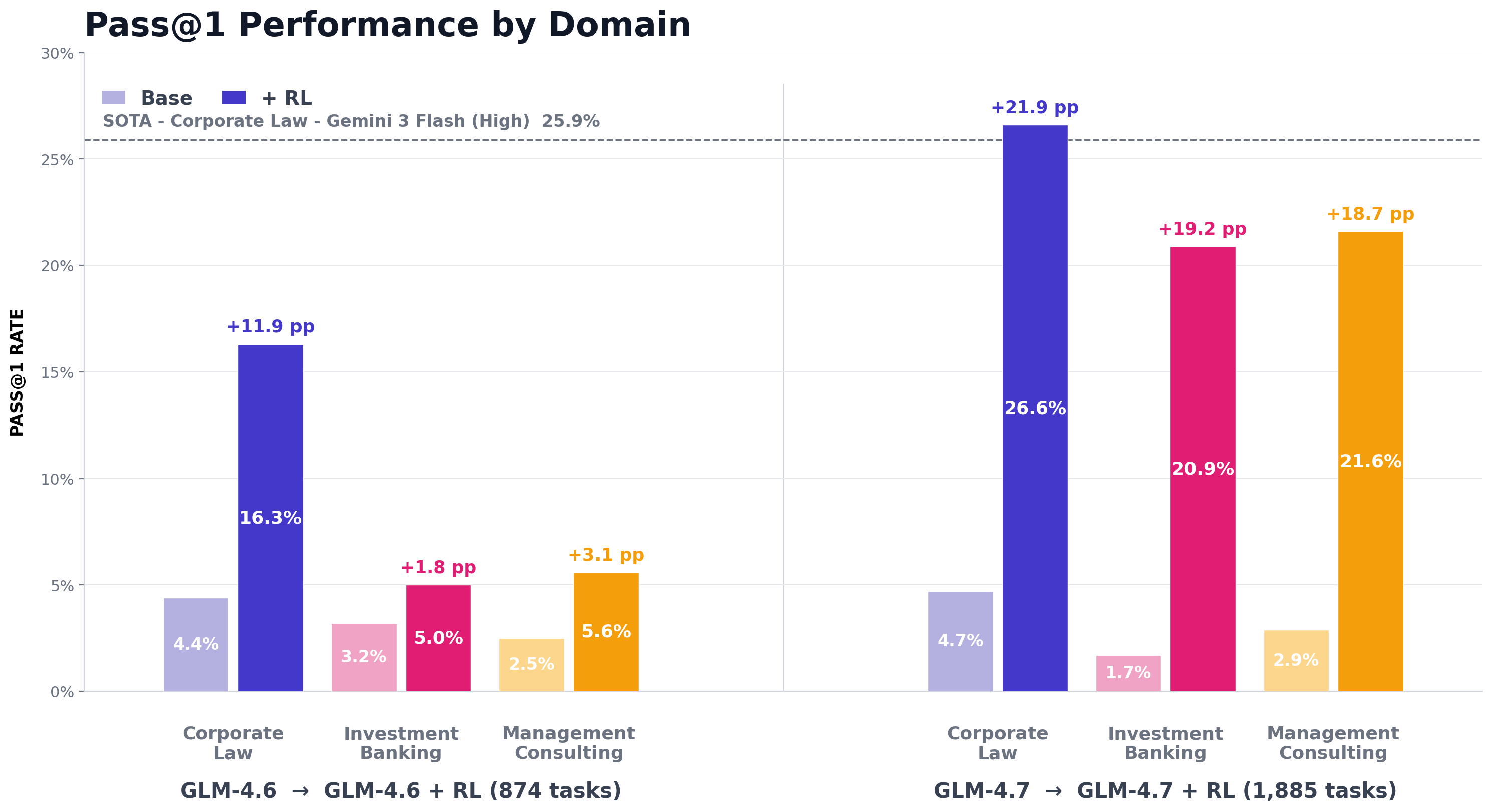
In January, we showed that fewer than 1,000 expert-labeled tasks could double an open-source model's performance on APEX-Agents, our frontier benchmark for cross-application, long-horizon tasks in professional services. The training trendline was near-linear, signaling that more data would keep yielding gains so we scaled the dataset for Applied Compute to almost 2,000 high-quality cases. They post-trained GLM 4.7 and their new model Applied Compute: Small is now top of the APEX-Agents leaderboard in corporate law, with a Pass@1 score of 26.6% and a mean score of 54.8%.
The new model places 4th on the APEX-Agents leaderboard overall by mean score, a dramatic improvement on GLM-4.7 which is 17th. This is significant as GLM-4.7 is a strong open source model, but at 355B (MoE) and a total context length of 200k, it is much smaller than the commercial-grade models that it is now competing with.
How has the model’s behavior changed?
To understand what changed, we compared the trajectories of GLM-4.7 and Applied Compute: Small head-to-head. On average, Applied Compute: Small consumes roughly 2 million tokens per trajectory, 4x the token usage of GLM-4.7, and much closer to frontier models like Gemini 3.1 Pro and Claude Opus 4.6. But GLM-4.7 can be served for as little as $0.50 per million input tokens, while Opus 4.6 costs 20× that for long tasks and GPT 5.2 Pro costs 40×. This represents a substantial difference in the economic utility of each dollar spent on tokens.
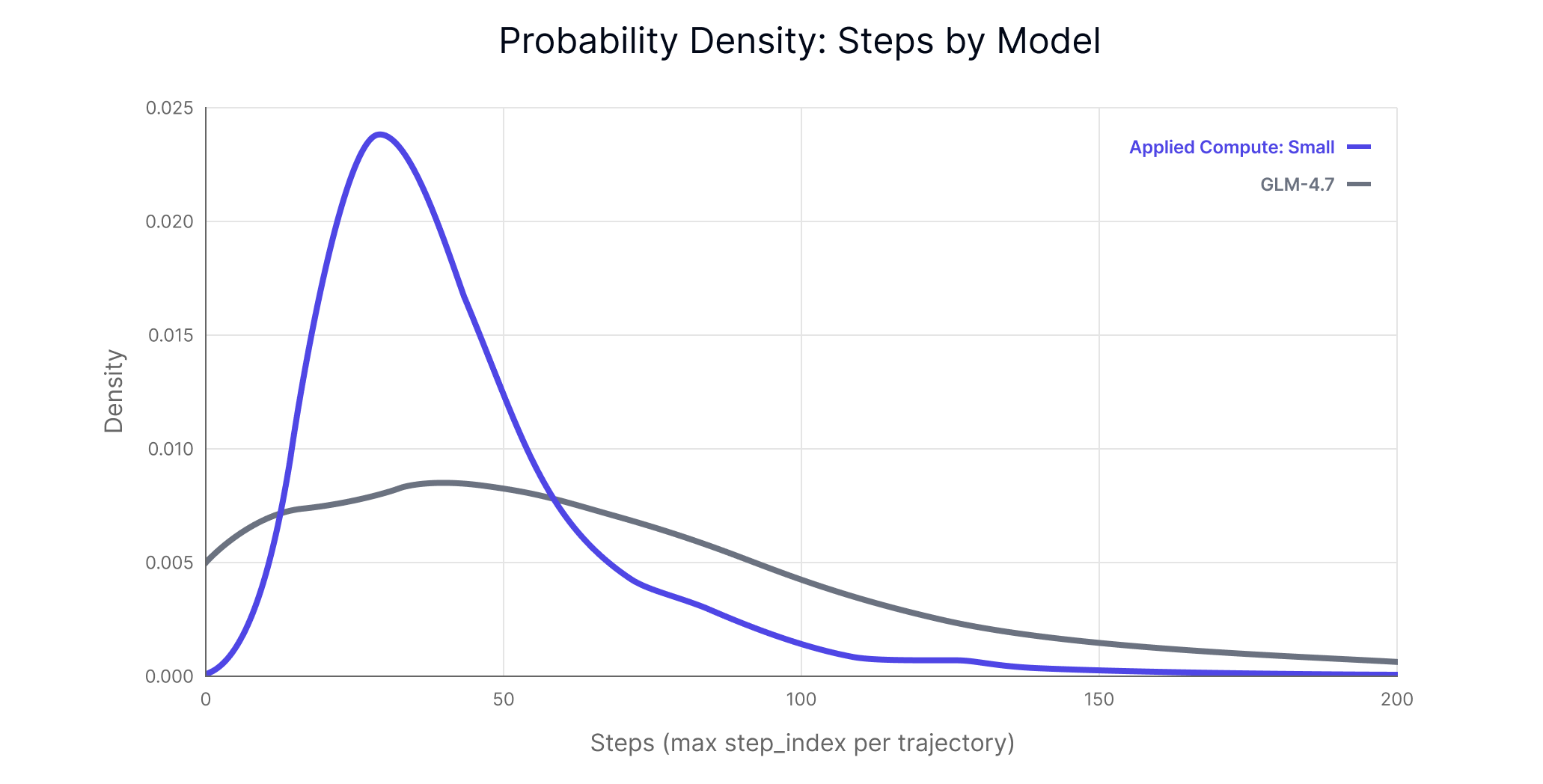
Applied Compute: Small completes tasks in far fewer steps (43 vs. 72) than its base model. As Figure 1 shows, its step distribution is tightly concentrated, while GLM-4.7 exhibits a long tail extending past 150 steps. This is driven in part by doom-looping behavior, where GLM-4.7 repeatedly attempts broken tool calls or falls into cycles. Applied Compute: Small, by contrast, is more efficient at locating the files it needs—but because those files tend to be large, it incurs substantial token costs when reading them in.
Applied Compute: Small learnt to rely on code execution, using it at least once in 98% of trajectories. It also searches the file system 96% of the time, and typically either reads at least one PDF (84% of the time) or xlsx file (63% of the time). In contrast, GLM-4.7 only uses code execution in 19% of trajectories and often fails to read in the right documents. This is a critical limitation given that APEX-Agents requires navigating the file system to complete each task.
Has the model lost any capabilities?
We evaluated GLM-4.7 and Applied Compute: Small on two industry standard benchmarks, HLE and GPQA, to measure whether Applied Compute: Small has regressed, potentially losing other valuable capabilities while improving at APEX-Agents. We see a small improvement on GPQA of 0.4pp and a small decrease on HLA of 1.3pp. Neither of these differences are statistically significant and, acknowledging that we only tested on two benchmarks, we did not find evidence of Applied Compute: Small losing general capabilities.
![Performance of GLM-4.7 and Applied Compute: Small on industry benchmarks. Note: Reference benchmark scores were taken directly from https://z.ai/blog/) [1]](https://cdn.sanity.io/images/h6s14f4z/production/5a31a16a5d8ed234927c71ab8989ac7b25d4b070-1466x372.png)
We also looked at the length of the final outputs. On APEX-Agents, the average number of tokens in Applied Compute: Small’s final outputs is ~3x that of GLM-4.7 (1,956 vs 631). This is a moderate increase, but indicates that Applied Compute: Small is not just scattergunning information and hoping for the best. The difference is also inflated by the large number of cases where GLM-4.7 responds with a short statement that it cannot find the right files.
Conclusion
In January, we showed that fewer than 1,000 expert-labeled tasks could nearly double an open-source model's performance on APEX-Agents. By scaling to 2,000 cases, Applied Compute: Small now leads the corporate law leaderboard outright, outperforming models that are orders of magnitude more expensive to serve.
This result reinforces a broader thesis at Mercor -- quality expert data, paired with the right post-training infrastructure, can close gaps on model performance. The behavioral changes we observe (more effective tool use, fewer wasted steps, richer final outputs) suggest that the model is not just memorizing patterns but learning the requirements of professional work.
For Mercor, post-training is a vital part of our stack. It validates the quality of our data, helps us allocate experts to produce measurable and generalizable performance gains, and drives our failure analyses, letting us understand not just how often models fail, but why, and how to fix it. To learn more about APEX-Agents, data quality, and post-training at Mercor, contact [email protected].
Applied Compute helps enterprises build and own AI agents trained on proprietary data, aligned to specific workflows, and designed to continuously learn. To learn more, reach out to [email protected].
Footnotes
[1] HLE and GPQA are reported as avg@1 and avg@3 respectively. 95% confidence intervals are calculated naively using the normal approximation to the binomial.
[2] Base models were evaluated using the ReAct agent harness, as introduced by Yao et al. (2022) (arXiv:2210.03629). While this richer scaffolding often improves raw task performance, it is not conducive to training or efficient inference as the system prompt changes throughout the trajectory. As such, post-trained models were trained and evaluated using a simple loop agent architecture. For implementation, see here: https://github.com/Mercor-Intelligence/archipelago