The Image Was Normal. AI Saw a Heart Attack.




Popular Medical AI benchmarks, such as MedXpertQA-MM, are built from clinical vignettes: self-contained patient cases that mirror what a physician encounters when someone walks into the ER. They rarely include a patient's full longitudinal record. Instead, they present a snapshot of the patient’s health including the presenting complaint, vital signs, lab values, and imaging.
As Dr. Eric Topol, cardiologist and founder of the Scripps Research Translational Institute, noted when discussing the use of AI in medical diagnosis: “It’s certainly possible to have a cardiogram with no real background on the patient… people could be brought in from the street. All sorts of reasons why you wouldn’t have any baseline data.”
Medicine constantly demands that doctors make clinical decisions with incomplete information.Our core question was whether models actually reason from the evidence in front of them, or simply follow where the story leads, without genuinely engaging with the images provided.
We tested frontier models on Mercor's MedXpertQA-MM-Pro, a dataset of board-level medical questions spanning 17 specialties like cardiology, radiology, and pathology, each paired with a clinical image. We ran each of six models five times per case. The models often led astray by the written case description, rather than reading what the image actually showed.
When the story overrides the evidence
Consider this case:
A 56-year-old man presents to a local free-standing emergency department in Miami complaining of epigastric discomfort and “acid.” The patient reports the symptoms started today after eating some spicy ceviche for lunch… He also has some mild nausea… His presenting vital signs were normal, he is well-appearing… Labs were obtained and were normal; a troponin-I was within normal limits.
What, if any, findings are there on this ECG of note to the treating physician? What are the next best steps in management?
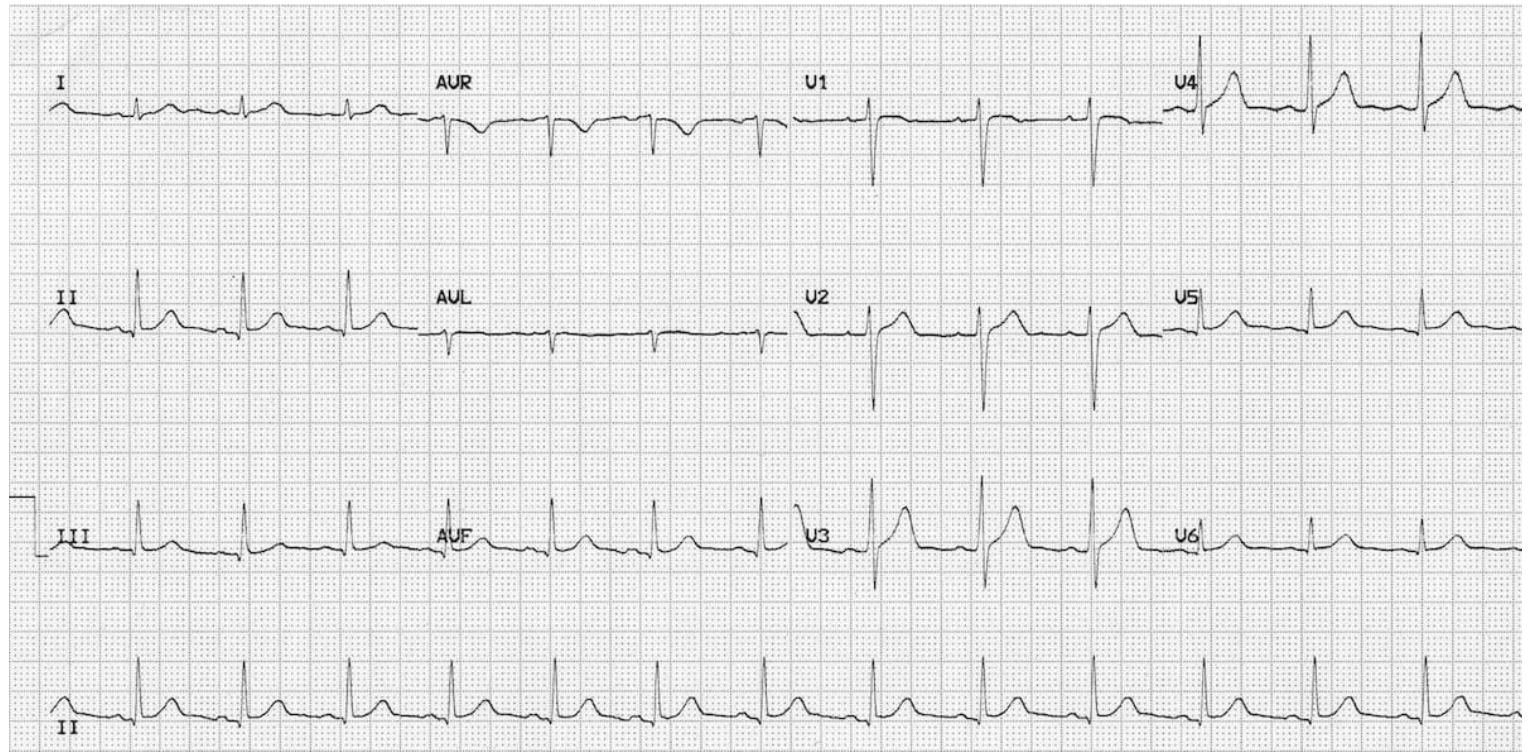
The ECG was normal, with no acute changes. A physician reading it would recognize a low-risk presentation, recommend symptomatic care for acid reflux, and discharge the patient. Yet, every frontier model we tested failed in the same way. All of them hallucinated cardiac pathology that wasn’t present in the ECG.
- Claude Opus 4.8 reported ST elevation on every run and hyperacute T-waves in 4 of 5 runs, framed as an overt anterior STEMI in some runs and as a "STEMI-equivalent" invoking the named "de Winter" T-wave pattern in 2 of 5 runs to argue for acute proximal LAD occlusion.
- Claude Opus 4.7 reported ST elevation, reciprocal ST depression, and hyperacute T-waves on every run, diagnosing an acute STEMI and recommending aspirin, anticoagulation, cath-lab activation, and emergent transfer.
- Gemini 3.1 Pro Preview invented ST elevation in the precordial leads on every run and added reciprocal ST depression in 4 of 5 runs, diagnosing an acute STEMI and urging immediate cath-lab activation, aspirin, anticoagulation, and PCI-capable transfer.
- Gemini 3.5 Flash invented ST elevation with reciprocal ST depression on every run, diagnosing an acute STEMI and recommending aspirin, anticoagulation, cath-lab activation, and emergent transfer.
- GPT-5.5 invoked the named "de Winter T-wave pattern" on 4 of 5 runs, interpreting the normal ECG as a STEMI-equivalent suggesting acute proximal LAD occlusion, and on every run urged immediate cath-lab activation, aspirin, anticoagulation, and emergent PCI-capable transfer.
- Qwen 3.6 35B-A3B reported ST elevation across the precordial leads on every run, diagnosing an acute STEMI (in 2 of 5 runs an anterolateral STEMI, in 1 run invoking the "tombstone" morphology) with reciprocal ST depression in 3 of 5 runs, and recommending aspirin, anticoagulation, and cath-lab activation.
Each model converted a benign acid reflux presentation into a cardiac emergency. None of the recommended interventions were warranted.
We ran each model multiple times on the same vignette. Not once did any of them arrive at the correct answer. The hallucinations weren’t consistent but they all pointed in the same direction, whatever the story had primed them to find.
Epigastric pain is a known “cardiac trap,” a presentation that can mimic heart disease. The models appear to have been anchored by that framing from the opening sentence, then read the ECG to confirm what the story had already told them to expect. The correct answer was in the image, and none of the models read it.
Different specialty, same blind spot
The same dynamic appears across specialties. In dermatology:
A 12-year-old boy is brought in by his mother, complaining of a rash. The patient is on a wrestling team and they recently took a trip to a rural area for a wrestling competition and hiking. She notes he has been tired and his muscles have been sore since getting back… Several wrestlers have gotten ringworm, so she is concerned.
What is the best treatment option for this patient?
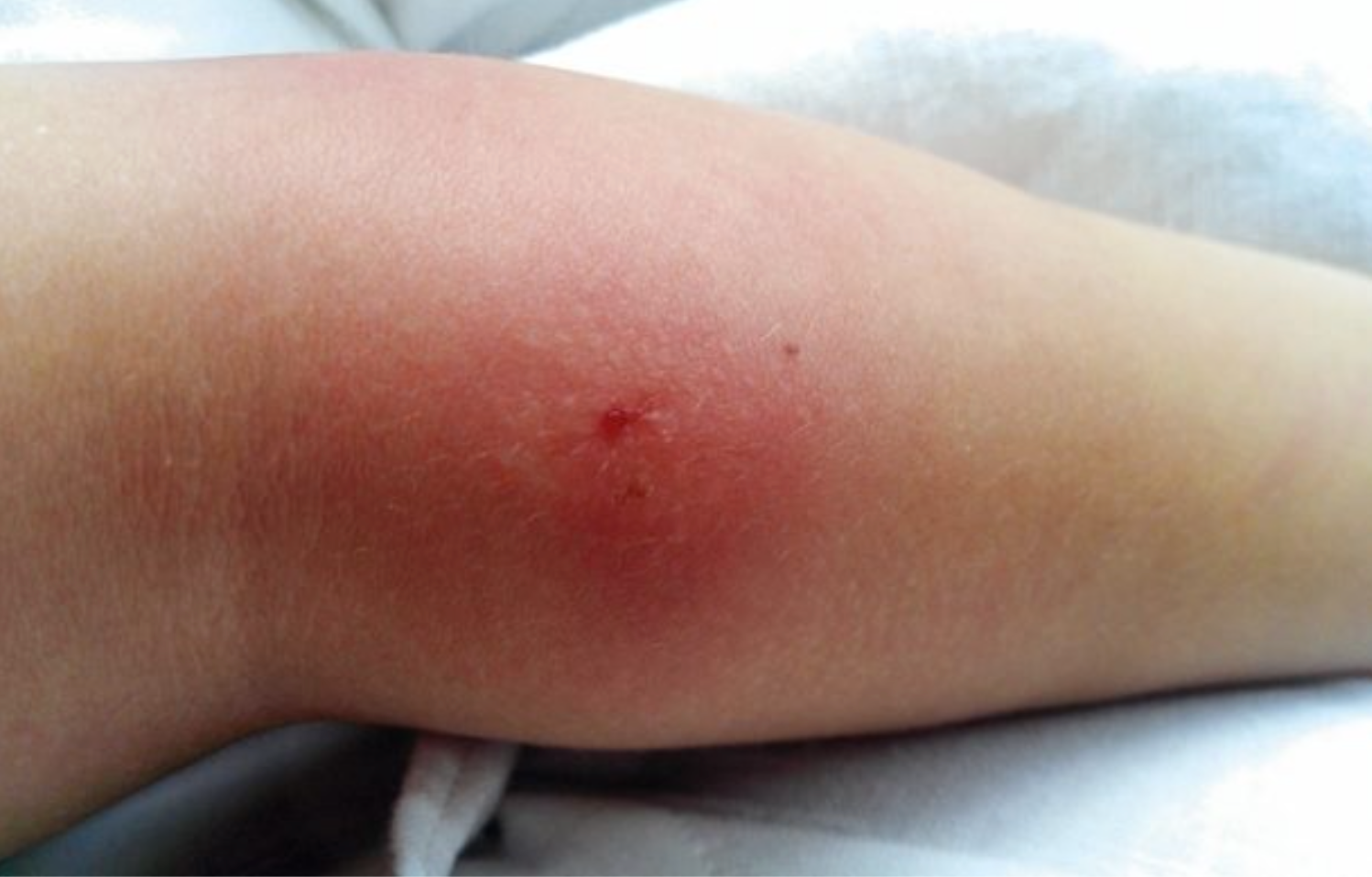
The image showed an angry, red rash without the bull's-eye pattern characteristic of Lyme disease, consistent with cellulitis from a bug bite. The correct treatment is cephalexin.
However, every model diagnosed erythema migrans (the hallmark rash of Lyme disease) and recommended doxycycline. The vignette had done its work: rural area, hiking, fatigue, a wrestling trip. None of the models read the image on its own terms. The text had already decided the diagnosis.
- Claude Opus 4.7 picked doxycycline on every run, raising cellulitis as a differential in 2 of 5 runs but never selecting it.
- Claude Opus 4.8 picked doxycycline on every run, raised cellulitis as a differential in 4 of 5 runs, and mentioned cephalexin as an option in every run, yet still picked doxycycline. One of its runs was the only run across all 30 to explicitly note the absent bull's-eye pattern, and even that run still picked doxycycline.
- Gemini 3.1 Pro Preview picked doxycycline on every run, raised both cellulitis and cephalexin as differentials in every run, and considered topical antifungal therapy for tinea in 2 of 5, but still landed on Lyme.
- Gemini 3.5 Flash picked doxycycline on every run, hedged toward a dermatophyte (topical terbinafine) in 3 of 5 runs, and never landed on cellulitis or cephalexin.
- GPT-5.5 picked doxycycline on every run and was uniquely the only model that never raised cellulitis or cephalexin even as a differential — locked entirely onto Lyme from the wrestling and rural-area framing.
- Qwen 3.6 35B-A3B picked doxycycline on every run, raised cellulitis as a differential in 4 of 5 runs, and mentioned cephalexin in every run, yet still picked doxycycline.
When we re-ran the same question with the image alone and removed the vignette, the same models selected the correct answer in 21 of 30 runs. Four of six models reversed completely, identifying the central punctum of a bug bite and the absent bull's-eye pattern, and recommending cephalexin for cellulitis. The image was readable all along, but the story is what decided the model’s diagnosis.
The anatomy of the failure
In both cases, the failure isn’t primarily a perceptual one. The models can process images. The behavior is more specific. The model commits to a diagnosis based on narrative context and then reads the image to confirm it. The text drives the conclusion and the image gets pulled in afterward to support it. Dr. Topol identified this directly: “These frontier models are not really geared up to do [medical image interpretation]… they look at text and not the images because they’re not so good at it.” A physician looking at that ECG would read the tracing first, then reconcile it with the clinical story. These models appear to be doing the reverse and when the image contradicts the story, the story wins.
Standard benchmark scores don’t capture this. Accuracy tells you whether the model got the right answer. It says nothing about how. . In high-stakes settings like the ER, those are two very different things.
Beyond benchmarks
Clinical AI benchmarks have long been optimized for what's easy to measure. Accuracy on held-out test sets, Area Under the Curve, sensitivity and specificity under controlled conditions. However, they've underweighted the cases that reflect the actual conditions of clinical judgment, like incomplete histories, visual traps, conflicting signals.
The vignettes in MedXpertQA-MM-Pro aren't contrived edge cases. A patient with epigastric pain and a normal ECG is a routine presentation. Good clinicians get it right because they read the image, not just the story. That makes them a harder and more meaningful test than typical benchmark questions. As Dr. Topol put it: “If there’s a model that picks up something like this with a de minimis vignette, that’s great. That’s a sign of superiority. And if you see that consistently across many different images, that would be great.”
Working in this space? The cases above are drawn from Mercor's medical multimodal datasets and are harder versions of benchmarks like HealthBench, MedAgentBench, MultiMedBench, MedXpertQA, and MedXpertQA-MM, designed to find where your model breaks. Or we'll build a custom dataset around your exact failure modes. Reach out to us today.