Introducing APEX-Agents



Today, we’re introducing APEX-Agents, our new benchmark designed to test how well AI agents complete real, long-horizon tasks in investment banking, consulting, and corporate law.
It’s the latest addition to the AI Productivity Index (APEX), Mercor’s family of benchmarks that measure economically valuable capabilities, joining APEX for tool-free evals and ACE for consumer applications.
With APEX-Agents, we set out to find if today’s AI agents do economically valuable tasks. Are they ready to work with teams, in real software tools, and deliver client-ready work?
Workplace context is messy, incomplete, and spread across documents and chat threads. Tasks take hours, not seconds.
Most existing benchmarks don’t reflect that. They evaluate models on isolated prompts or narrow skills. They don’t measure whether an agent can navigate multiple workflows and produce something a manager or client would accept.
That is why we approached APEX-Agents differently. Every task is designed to mirror the complex work professionals do, the tasks they wish an AI agent could help with, and identify where current models struggle to perform reliably.
Our approach
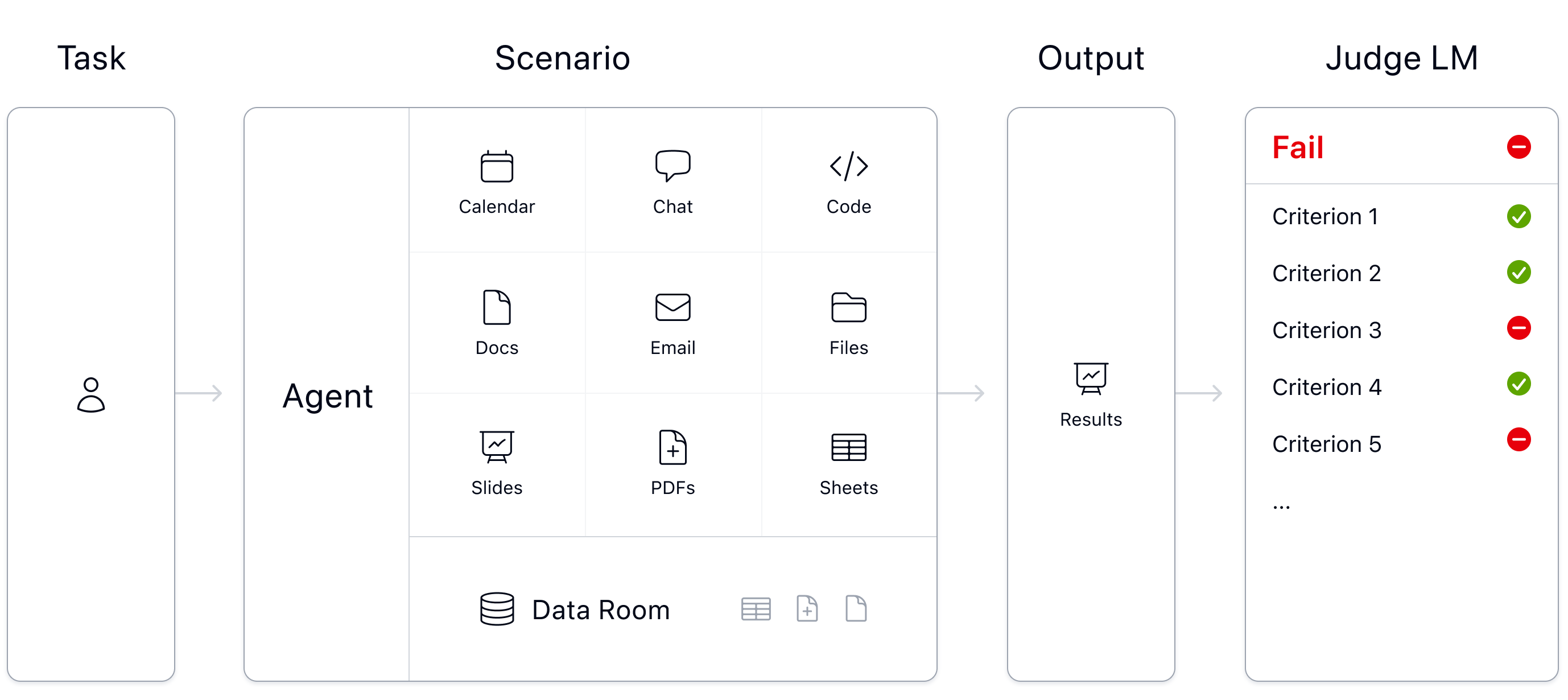
APEX-Agents simulates the demands of the profession to challenge agents to navigate instructions, manage complicated file systems, and produce outputs that justify a professional fee.
Our four-step approach:
Surveys: We started out by surveying hundreds of experts from professional services including Goldman Sachs, McKinsey, and Cravath to understand how they spend their time.
Scenarios: A team of Mercor experts—Vice Presidents, Managing Directors, and Managers with five-to-ten years’ experience at top-tier firms—worked in Google Workspace, simulating how coworkers would collaborate on a project.
This might look like a week-long consulting project for a fictitious European oil & gas company focused on cost-cutting measures.
We worked with Box to define what a real-world file system looks like. We mapped rigorous, domain-specific challenges to the complex file structures found in a mix of industries, resulting in datarooms that truly simulate the daily workflow of a professional.
The result is a high-context workspace that mimics what professionals navigate every day.
Task creation: Using these custom scenarios, the experts defined specific tasks and the exact grading criteria that define what “client-ready” means. Each task includes 1–10 pass/fail criteria.
Harvey AI provided early feedback on the design, scope, and realism of the corporate law worlds. They confirmed the complexity and value of the tasks in APEX-Agents, validating that they reflect the work of top lawyers at Fortune 500 enterprises and law firms.
Evals: We deployed AI agents inside these worlds using our open source evaluation infrastructure, Archipelago, to measure whether they finish the work correctly.
The findings
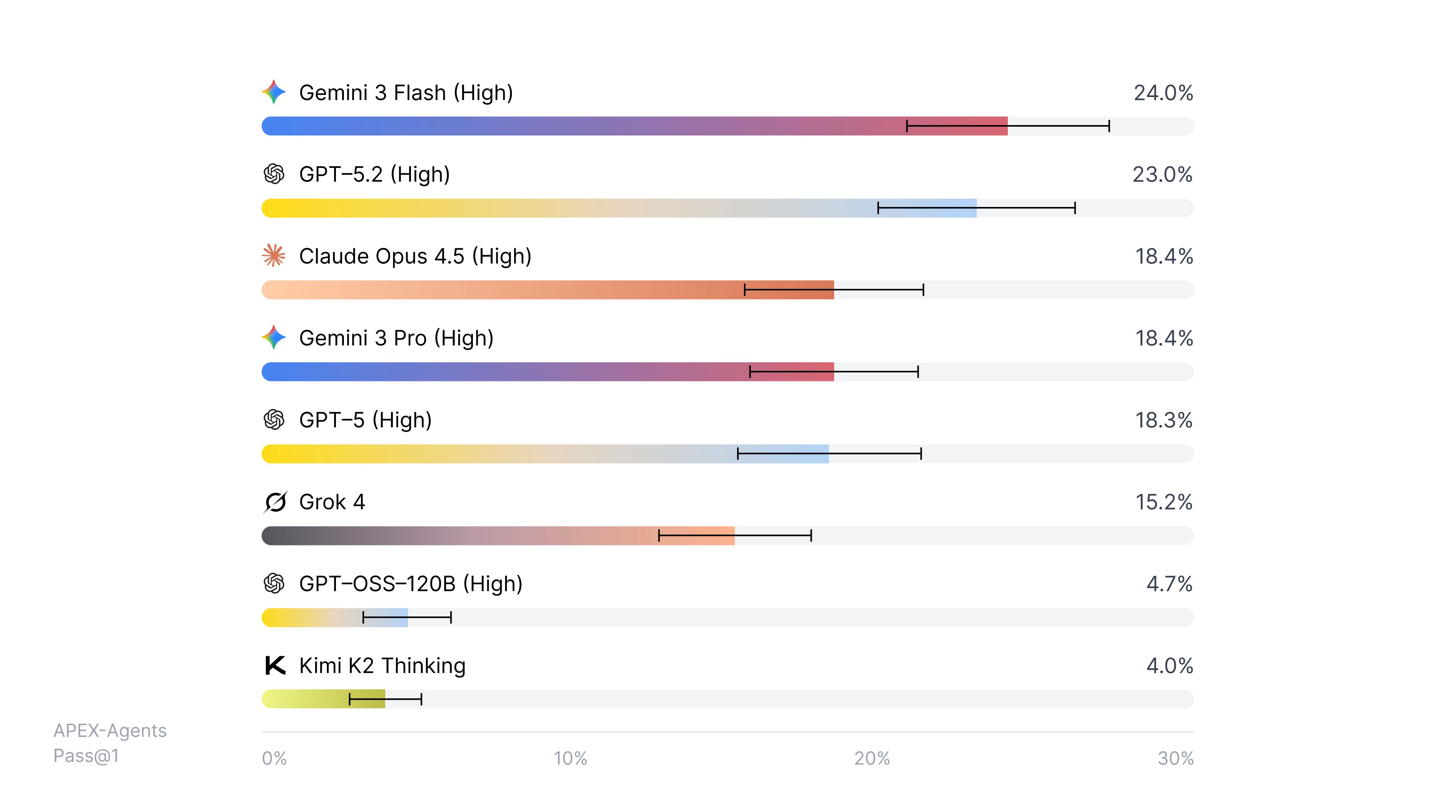
Frontier models successfully complete less than 25% of tasks that would typically take professionals hours. With multiple attempts, performance improves but the gap remains large. Even with 8 tries, the best agents can only complete 40% of the tasks.
Many agents fail due to lack of capability, but because they can’t manage ambiguity, find the right file, or hold context across the entire workflow.
No model is ready to replace a professional end-to-end.
Open source
We have released the entire benchmark open source via Hugging Face with a CC-BY license and Archipelago, our infra, eval service, and set of apps, is available as an open source repo on GitHub.
Read the full research paper on arXiv.