Introducing the AI Productivity Index for Software Engineering






Introducing APEX-SWE, a new benchmark created in collaboration with Cognition. It measures whether frontier AI models can handle real software engineering work – shipping systems, diagnosing failures, and implementing fixes.
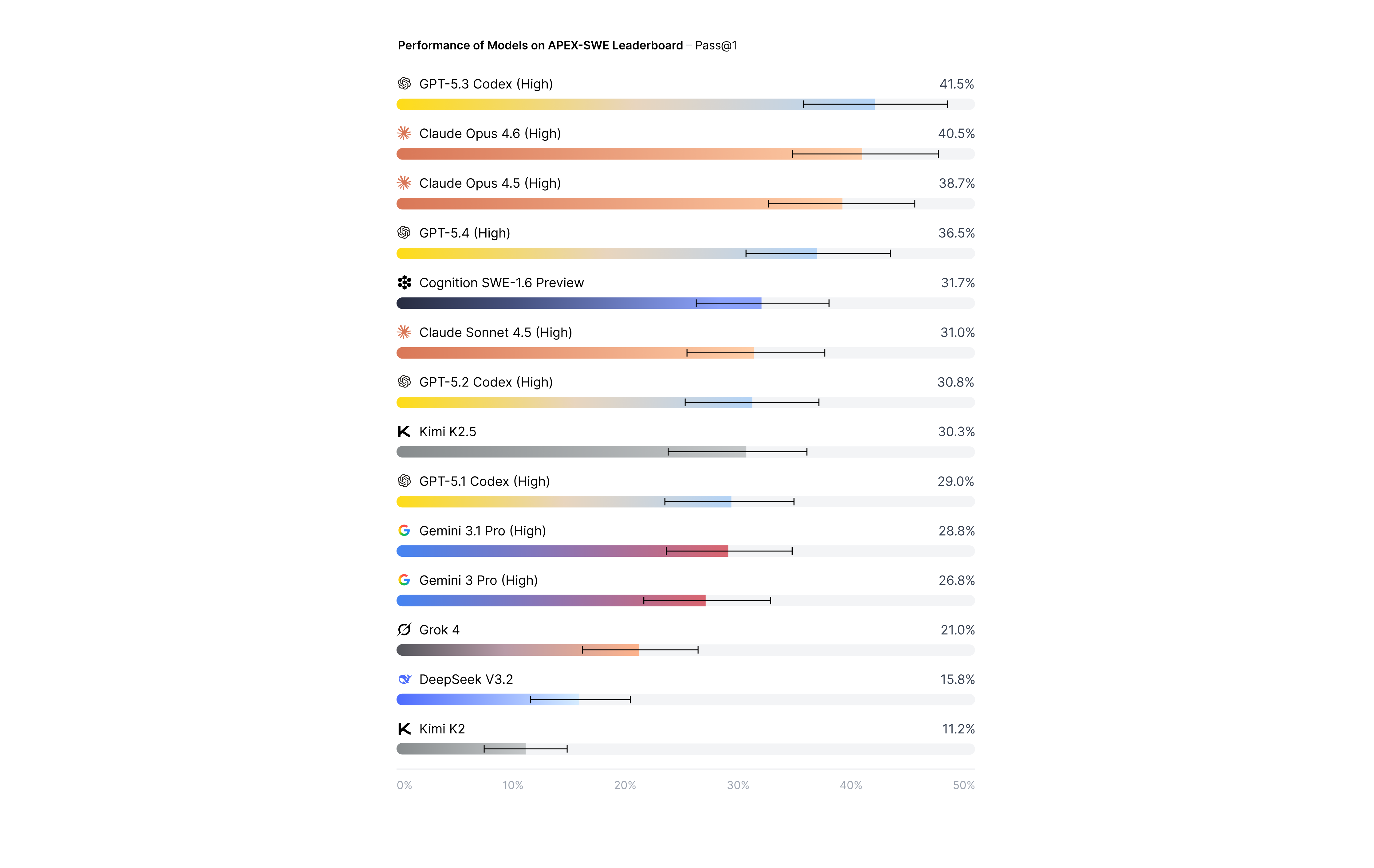
Our results show that even top performing AI models hit a wall when tasked with the complexities of real-world software engineering. At the time of release, the top score on the APEX-SWE leaderboard is GPT-5.3 Codex at 41.5% Pass@1, leaving plenty of room for hillclimbing.
Cognition was critical to making this benchmark reflect the expectations of software engineers. They reviewed a subset of integration and observability tasks, created by SWEs hired through Mercor’s platform, pressure-testing how real production systems actually break and get fixed. The resulting tasks reflect the expectations agents must meet to be useful in real software engineering work.
APEX-SWE builds on Mercor’s family of benchmarks for evaluating AI models at economically valuable work, including APEX-Agents, the AI Productivity Index (APEX), and the AI Consumer Index (ACE).
AI coding models and assistants are now a core part of software engineering, with recent industry reports indicating that over 90% of developers use AI coding assistants. Nearly half of all code at major technology companies is AI-generated.
Traditional coding benchmarks have become saturated. GPT-4 has improved from 67% to 90% on HumanEval in just two years, and the most recent Opus models consistently score over 75% on SWE-bench Verified. OpenAI has declared some SWE benchmarks contaminated, with models able to reproduce original patches verbatim from task IDs alone.
However, even before saturation, these benchmarks presented a misleading picture of AI models' real-world coding ability. According to IDC, developers spend only 16% of their time writing code and building new features. The remaining 84% involves CI/CD, infrastructure monitoring, deployment, and debugging.
Professional software engineering extends far beyond writing short functions or patching a single file. Real production environments involve cross-platform integration, infrastructure provisioning, and debugging production failures with incomplete information.
Leaderboard results
All of the models we evaluated fail to reliably solve the real-world production software engineering tasks in APEX-SWE.
GPT-5.3 Codex (High) tops the leaderboard at 41.5%, followed by Opus 4.6 (High) at 40.5% on Pass@1 and Opus 4.6 (High) at 38.7%.
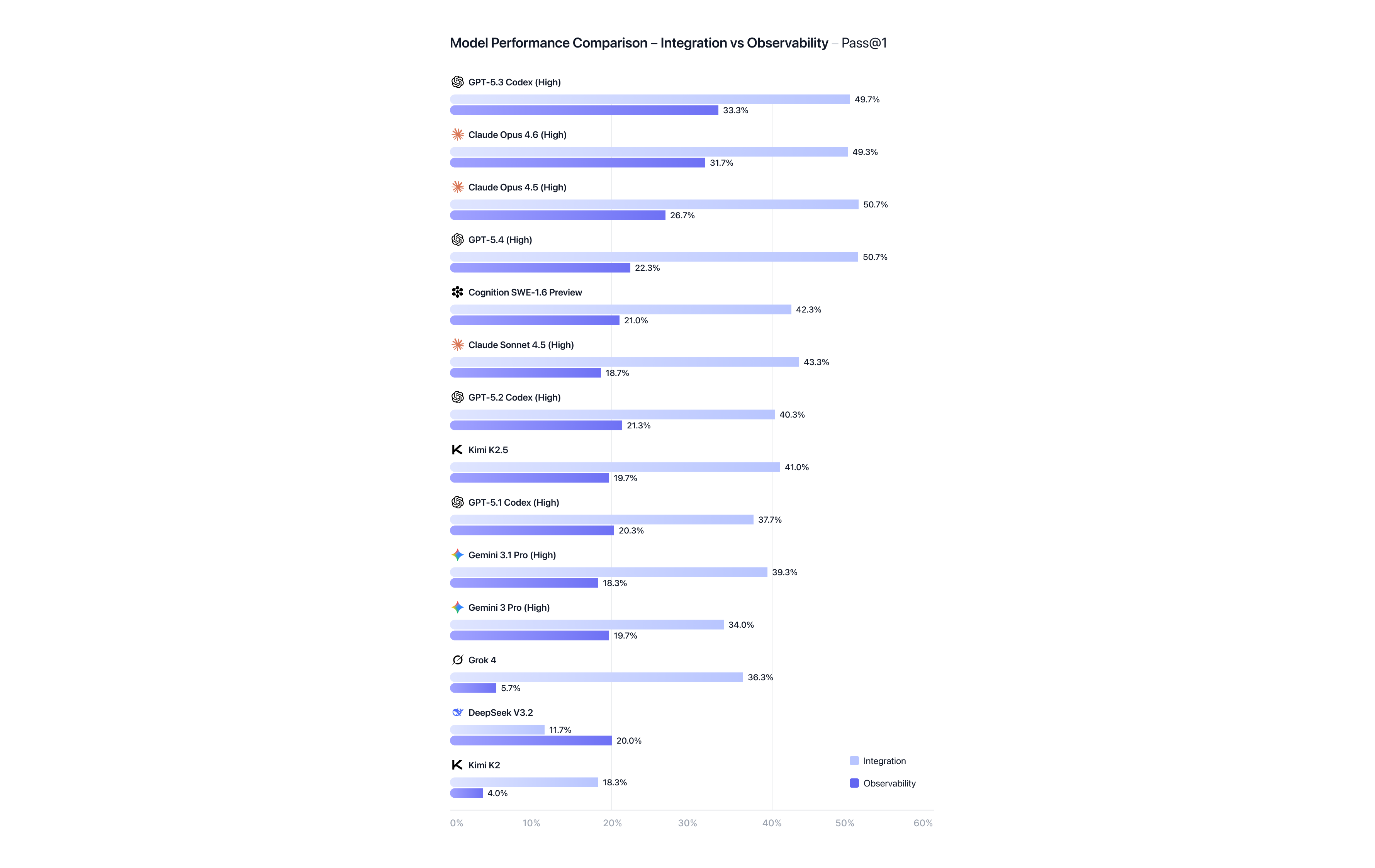
APEX-SWE is split evenly between two task types that reflect real-world software engineering work:
- Integration tasks, which require constructing end-to-end systems across heterogeneous cloud primitives, business applications, and infrastructure-as-code services.
- Observability tasks, which require debugging production failures using telemetry signals such as logs and dashboards, as well as unstructured context.
Models perform better on Integration tasks than Observability tasks. For Integration, Claude Opus 4.5 (High) and GPT 5.4 (High) lead at 50.7%. Observability scores are lower overall, with GPT 5.3 Codex leading at 33.3% Pass@1. For both task types, top-performing models demonstrate strong capabilities but still do not meet the production bar.
For both task types, when models succeed they demonstrate epistemic reasoning—treating their generated code as a hypothesis that must be tested against the actual system state before being finalized. This iterative and careful approach results in more successful code executions as problems are overcome through debugging.
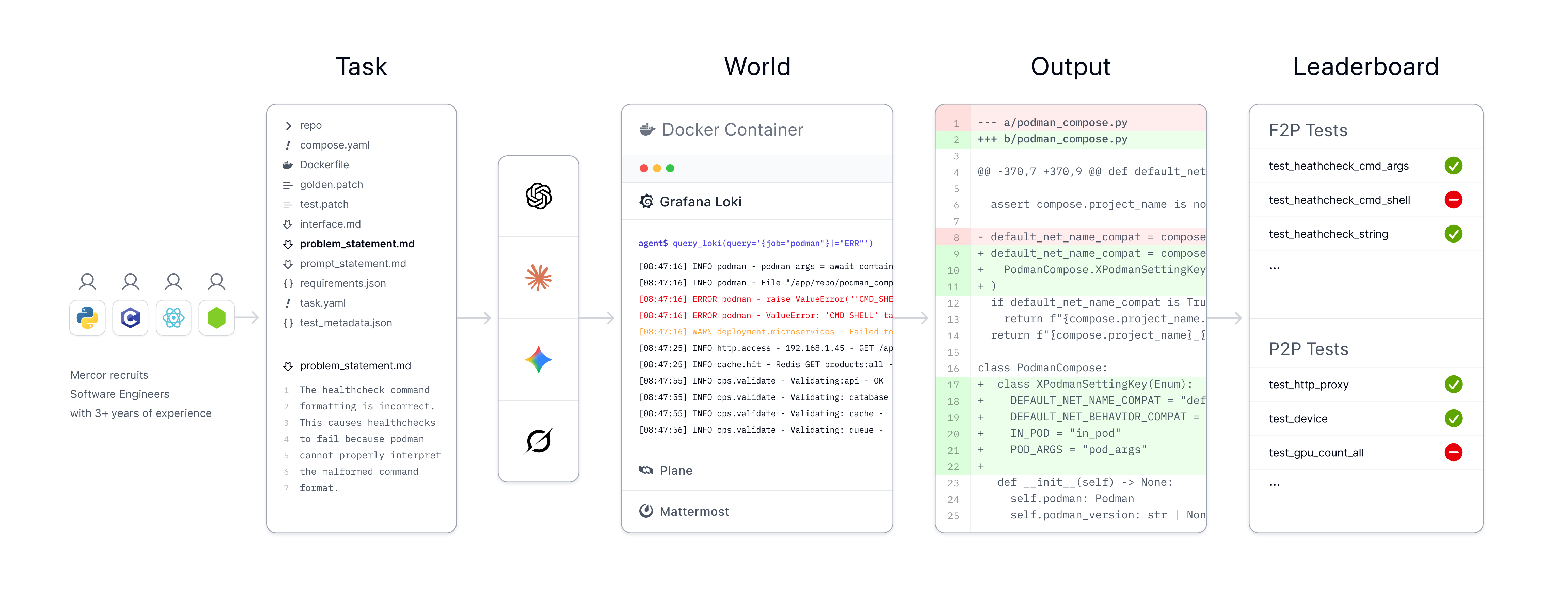
Our process
Each integration task contains an environment for the agent to operate it. They all include an ephemeral PostgreSQL database and Plane, as well as six other services: LocalStack (56%), which emulates AWS primitives such as S3, Lambda, DynamoDB, and Kinesis, EspoCRM (35%), MailHog (33%), Mattermost (32%), Medusa (31%), and Zammad (26%). Tasks were created by software engineers with 3+ years of experience who ran validation tests and created gold standard outputs.

Each observability task deploys a containerized environment orchestrating five services: a client workspace, Loki and Promtail for log aggregation, Grafana for visualization, and Plane/Mattermost for ticket and chat context. Engineers scripted synthetic logs (500 to 1,000 lines of normal operation mixed with 10-20 lines of bug symptoms) and chat history to replicate a production failure, as well as Dockerfiles, task metadata, and patches. Tasks were derived from real-world GitHub Issue-PR pairs, sourced from repositories with at least 350 stars that we filtered for complexity and stability. Observability tasks are distributed across five widely-used languages: Go (30%), Python (25%), TypeScript (25%), Java (10%), and C++ (10%).
Open source
We have released an open-source dev set via Hugging Face (n=50) with a CC-BY license, and our eval harness is available as an open-source repo on GitHub. The full leaderboard comprises n=200 tasks that are heldout and hidden, with a similar distribution to the open-source set. Read the APEX-SWE technical report.
We thank all the software engineers on the Mercor marketplace who contributed their time to creating APEX-SWE.