Agent Eval Systems

Abstract
Enterprise agents increasingly operate across tools, documents, databases, and systems of record. Their value depends not only on model capability, but on whether their work can be measured, diagnosed, improved, and safely deployed. We present a framework for evaluating enterprise agents using verifier-backed judgments over agent trajectories and outputs. A verifier is an isolated program or agent that inspects a run, returns a normalized score in [0, 1], and explains the basis for the judgment. Verifiers can be scoped to trajectory behavior, final artifacts, external state changes, or combinations of all three.
The same evaluation object supports four deployment functions: production grading, offline regression tests, model and prompt benchmarking, and runtime quality gates. We define the core objects in this system, including task, environment, trajectory, output, verifier, activation condition, and cumulative reward, and describe how they compose into an optimization loop for agent improvement. We also describe the deployment architecture required for enterprise use, including customer-controlled data planes, configurable artifact sharing, and managed update postures.
The central claim is that enterprise agent reliability is an evaluation-systems problem. Agents improve when their work is converted into calibrated, hard-to-game feedback signals that can drive benchmarking, rollout decisions, and continuous optimization.
Part I. Evaluations
1. Definitions
An evaluation is a run plus a verifier-backed judgment of that run. The terms below are used consistently throughout.
1.1 Vocabulary
- Task. The instruction prompt given to the agent to execute. For example, "Create a 10-page due-diligence report on a target company," or "Screen a candidate in the applicant tracking system."
- Environment. The external APIs, databases, and integrations the agent can access during execution. It is the production environment for online runs, a mocked or synthetic environment for offline runs, and is sometimes unnecessary when the agent only reads inputs and writes to its own filesystem. For example, a mock document dataroom with a folder for the agent to deposit its output.
- Trajectory. The agent's full execution history: its reasoning and messages, and the inputs and outputs of every tool call.
- Agent output. The artifacts the agent emits and the external state it changes. For example, a deck created, an email sent, or a record advanced in a system of record.
- Verifier. A separate agent or script that grades the trajectory, the output, or both. It returns a score in [0.0, 1.0] and an explanation, and its definition carries a weight. A verifier runs in its own sandbox and may use a different model from the agent under test. For example, a verifier might compare a deck to a gold-standard reference, or check that a required file exists in the right folder.
1.2 Evaluation tests
Evaluation tests are the offline mechanism for measuring, experimenting on, and improving an agent before changes reach production. Each test is governed by three objects. The task is the prompt the agent must complete during the offline run. The offline environment is a mocked or synthetic version of the production instance, including the integrations, fixtures, and external state needed for the task. The verifier is the grader that inspects the resulting trajectory and output, then returns a score and explanation.
2. How evaluations work
2.1 Online and offline runs share one shape
An online run is invoked by a user in production. It uses the live production deployment, and production verifiers grade the run after completion. An offline run is launched from evaluation tests: the platform spins up the agent inside the offline environment, runs the task, and then applies the listed verifiers.
Figure 1. The evaluation shape. Online runs happen in production and are graded afterward; offline runs use the tasks, mocked environments, and verifiers defined by evaluation tests.
For online runs, each production verifier has an activation condition so irrelevant checks do not run. A deck-quality verifier activates only when the task or output indicates a deck was requested, and does not activate for a screening task. For offline runs, activation is usually simpler, because the evaluation tests already name the task, environment, and verifiers that should run.
2.2 One definition, three roles
A verifier definition is reused in three places. As a runtime quality gate, blocking verifiers can prevent delivery until the output clears a threshold, then return feedback to the agent for revision. In production grading, activated verifiers grade production runs after completion, adding quality scores and explanations to cost, latency, and tool telemetry. In offline experimentation, evaluation tests run when a model, prompt, skill, or harness change is proposed and quality needs to be measured before rollout.
2.3 The cumulative reward, and what verifiers grade
Each verifier states what it grades (trajectory, output, or both) and its relative importance. Scores are normalized to [0, 1] so they remain comparable across tasks, dashboards, models, and optimization runs. The cumulative reward is the normalized weighted average.
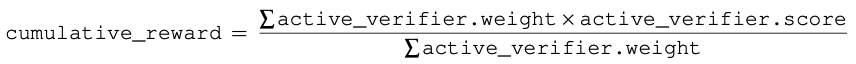
Inactive verifiers are excluded from both sums. Explanations are retained because the optimization loop uses both signals: the reward supports candidate selection, and the explanation guides the next revision.
2.4 Base versus agent-specific verifiers
Every agent inherits a small set of base verifiers for platform-wide expectations such as instruction following, required artifact delivery, and tool-calling efficiency. Each agent can then add agent-specific verifiers for domain quality. An account intelligence agent might add account context, source grounding, support risk, product usage, recency, and actionability verifiers. A verifier definition includes its model, activation prompt, verifier prompt, scope, production flag, blocking settings, threshold, and weight.
2.5 Worked example: enterprise account intelligence agent
Consider an agent asked to produce a strategic account brief for an upcoming executive meeting with a large customer.
The task is the user instruction and any attached requirements, such as the customer name, meeting objective, required sections, source constraints, and output format. The environment includes the CRM, prior meeting notes, support tickets, product usage data, approved internal documents, public company information, and the filesystem where the brief must be written. The trajectory records the agent's tool calls, source reads, extracted facts, intermediate drafts, and revisions. The output is the final account brief and any state changes made in connected systems. A verifier set for this task could include the following.
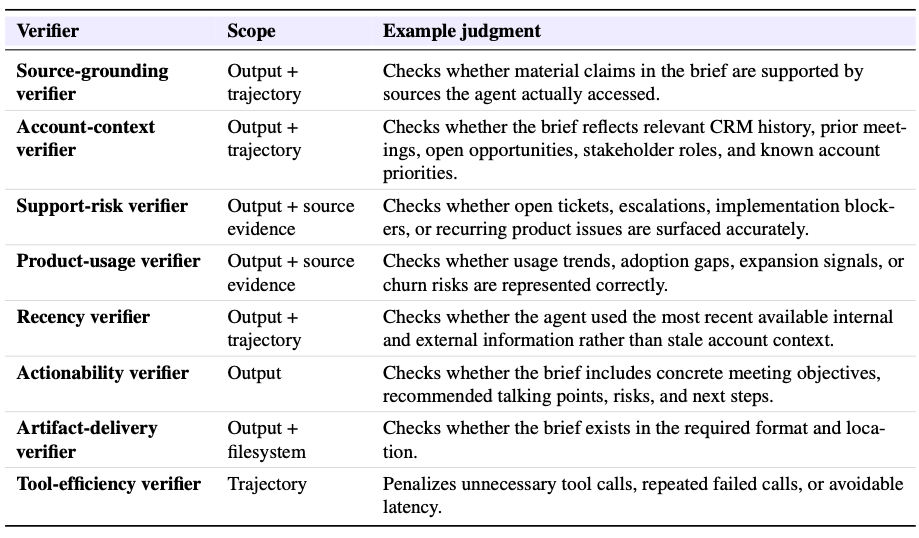
Each verifier returns a score and explanation. The weighted average becomes the cumulative reward for the run. If a blocking verifier fails, the agent can be asked to revise before the brief is delivered. If a non-blocking verifier fails in production, the run can be converted into a new offline evaluation test so future agent versions are checked against the same failure mode before rollout. The same structure generalizes beyond account intelligence. Once tasks, environments, trajectories, outputs, and verifiers are defined, they become a reusable package for benchmarking, optimization, rollout gates, and production monitoring.
Part II. Benchmarks and the optimization loop
3. The reusable package
Once an agent has evaluation tests, the same package can be reused for benchmarking, A/B tests, automated prompt optimization, rollout decisions, and model selection. The package has three parts. The environment is the agent's action space and external integrations, wrapped in a container together with mock tool calls. The tasks are prompts that cover the full distribution of work the agent must perform. The verifiers are attached to each task, producing scores and explanations that are combined by weight into the cumulative reward defined in Section 2.3.
The same grammar is portable. Tasks, environments, verifier definitions, weights, and scoring outputs can be adapted to external benchmark task and environment formats, which makes evaluation tests easier to port into outside benchmark systems while preserving customization for customer-specific tools, verifiers, and deployment constraints. The workflows below vary with different inputs, but they all consume the same bounded reward and verifier explanations.

4. The optimization loop
Optimization starts with the main agent and a task suite. The task suite is a set of representative offline evaluation tests, each with a task, environment, and verifier set. It defines what the agent is expected to do well, and provides the standard against which every candidate version is measured.
The loop optimizes a generator agent. At the beginning of the loop, the generator agent is initialized as a copy of the main agent: same prompts, skills, harness, and model configuration. From there, the generator agent becomes the moving target. Each iteration runs the current generator agent through the task suite, grades its performance, and then updates the generator agent based on the verifier feedback.

Figure 2. The optimization loop.
1. Initialize the generator agent. Start with the current main agent as the baseline. This creates the first generator-agent version.
2. Run the task suite. The generator agent runs across the offline evaluation tests. For each task, it acts in the test environment, produces a trajectory and output, and is graded by the relevant verifiers.
3. Collect reward and explanations. The verifiers return per-task scores, per-verifier explanations, and a cumulative reward. The reward shows how well the generator agent performed; the explanations describe why it failed or succeeded.
4. Call the fixer agent. The fixer agent reads the generator agent's current files, the task trajectories, the verifier scores, and the verifier explanations. It diagnoses the failures and edits the generator agent directly, updating prompts, skills, harness instructions, or other agent-layer behavior.
5. Advance the generator version. The fixer agent's edits create the next version of the generator agent. That updated generator agent is then rerun on the task suite.
6. Keep improvements. If the new generator version improves cumulative reward on the validation set, while staying within acceptable cost and latency bounds, it becomes the leading candidate. If it regresses, the system keeps the stronger prior version and continues.
5. What the loop depends on
The loop is only as good as three things, and it is worth being direct about where it is hard.
Verifiers can be gamed: if a verifier rewards a shortcut, the agent will learn the shortcut, so verifiers need to be deterministic where possible and calibrated against human judgment.
Coverage is a real constraint: the evaluation tests are only as useful as the slice of real work they cover, and gaps in the task distribution show up as blind spots in production.
And the strength of the improvement loop is bounded by how much signal is available to it: with little evidence from production, there is less ability to diagnose regressions, derive test environments, and validate updates.
That last point is a genuine tradeoff, not only a data-sensitivity question, and it is the subject of Part III.
Part III. Where this is differentiated
6. Where this is differentiated
Evaluation is the control point for the agent lifecycle. It determines which model to use, which prompt to ship, whether a harness change improved performance, and whether an output is ready for production. The team with the strongest evaluations can build the stronger agent, because it can measure the work that matters.
Mercor's advantage comes from doing this work in both frontier model development and enterprise deployment. For frontier AI labs, evaluation work requires decomposing complex tasks, defining quality bars, sourcing expert judgment, and building feedback loops that improve model behavior. For enterprise customers, the same evaluation discipline has to be adapted to agents that operate inside business workflows: reading internal documents, calling tools, updating systems of record, producing artifacts, and making recommendations that business teams can trust. Three capabilities decide whether that system works.
First, verifiers have to be hard to game. A weak verifier does not just miss problems. It trains the wrong behavior. Strong verifiers are deterministic where possible, calibrated against expert judgment, and designed to catch the failure modes that actually matter in production.
Second, coverage has to reflect the real distribution of work. Evaluation tests cannot only cover clean prompts and easy cases. They need to include ambiguous instructions, missing context, stale data, tool failures, conflicting evidence, and the edge cases that appear once an agent is used by real teams.
Third, domain expertise matters. A generic evaluator can check format, length, and surface-level completeness. It cannot reliably judge whether an account brief identifies the right risks, whether a support escalation is represented accurately, whether a market map is shallow, or whether a recommendation is commercially useful. Those judgments require practitioners who understand the work.
The differentiation is the combination of expert evaluation, hard-to-game verifiers, and a platform that turns those verifiers into measurement, experimentation, optimization, and rollout decisions. Mercor is not only deploying agents. It is deploying the evaluation system that makes agents measurable, improvable, and safe to update over time.